Большинство статей, описывающих новые методы машинного обучения (МО) в области поиска лекарств, содержат сравнительные анализы, сопоставляя их алгоритмы и/или молекулярные представления с существующими передовыми методами. Ранее было опубликовано много статей про улучшение оценки методов машинного обучения. О статистике и о том, как следует проводить сравнение методов. В этой статье фокус сосредоточен на наборах данных, которые мы используем для оценки и сравнения методов. Недавно опубликована статья об использовании набора данных MoleculeNet, выпущенный группой Pande в Стэнфорде в 2017 году, как «стандартный» бенчмарк. Это ошибка. В этой статье рассматривается набор данных MoleculeNet, и на его примере обсуждаются недостатки нескольких широко используемых бенчмарков. Кроме того, предлагаются некоторые альтернативные стратегии, которые могут улучшить усилия по бенчмаркингу и помочь развитию этой области. Давайте начнем с анализа бенчмарка MoleculeNet, который на сегодняшний день был процитирован более 1800 раз.
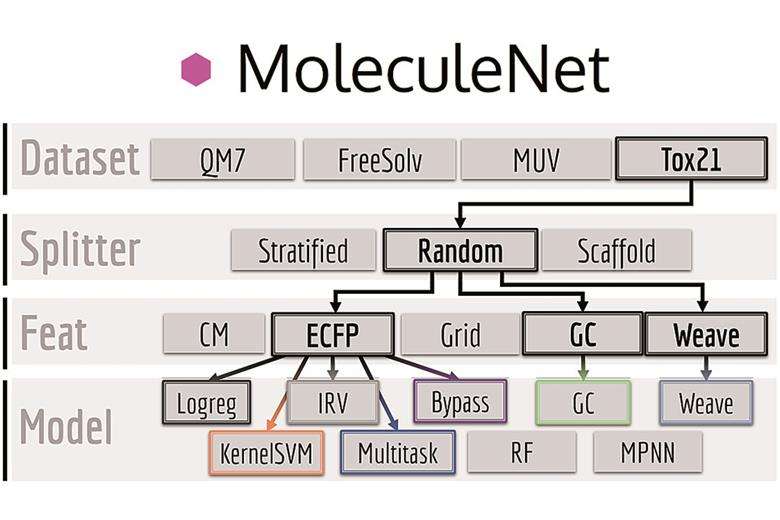
MoleculeNet
Коллекция MoleculeNet включает в себя 16 наборов данных, разделенных на 4 категории.
- Квантовая механика — Наборы данных в этой категории содержат трехмерные структуры молекул из базы данных Generated Database (GDB) и связанные с ними свойства, вычисленные с использованием квантово-химических методов. Ниже приводятся аргументы, что этот набор данных часто неправильно используется.
- Физическая химия — Набор измеренных значений для растворимости в воде, свободной энергии растворения и липофильности. Во многих отношениях эти бенчмарки не отражают, как используются соответствующие экспериментальные измерения на практике.
- Физиология — Наборы данных, состоящие из данных о проницаемости гематоэнцефалического барьера (ГЭБ) и различных показателей токсикологии. Сложность этих показателей делает данные менее подходящими для сравнения в бенчмарках.
- Биофизика — Пять наборов данных, исследующих различные аспекты взаимодействия белков и лигандов. Эти наборы данных обнаруживают несколько проблем, включая артефакты анализа, двусмысленно определенные химические структуры и отсутствие четкого разделения между обучающей и тестовой выборками. Об этом будет подробно рассказано далее.
Набор данных MoleculeNet содержит множество недостатков, что делает трудным, если не невозможным, делать выводы из сравнения методов. Эта статья не является нападением на авторов MoleculeNet. Авторы набора данных являются авторитетными учеными с признанными достижениями и большими научным опытом. Однако, если мы хотим двигаться вперед как область, нам нужно создать качественные бенчмарк-наборы данных, которые позволят нам сравнивать методы лучше. Мы не должны считать что-то стандартом для области просто потому, что все слепо используют это. Следует также отметить, что, эта статья фокусируется на MoleculeNet, другие широко используемые бенчмарки, такие как Therapeutic Data Commons (TDC), также имеют существенные недостатки. Ниже описаны некоторые критерии, которые, способствуют началу дискуссии о бенчмаркинге и том, что нам нужно от наборов данных.
Улучшение оценки методов машинного обучения и технические вопросы
Рассмотрим несколько относительно простых тем, связанных с сбором данных и отчетностью.
Корректные структуры
Для начала, бенчмарк-набор данных должен содержать представления химических структур, которые может разбирать широко используемые инструменты хеминформатики. Например, в наборе данных MoleculeNet для проницаемости гематоэнцефалического барьера (ГЭБ) содержатся 11 SMILES-нотаций с необарженными четырехвалентными атомами азота. Это неверно, так как четырехвалентный атом азота всегда должен иметь заряд. Из-за этих ошибок популярные инструменты хеминформатики, такие как RDKit, не могут обработать эти структуры. Существует множество статей, описывающих результаты на этом наборе данных, но ни разу не приводится, чтобы кто-либо упомянул, как были обработаны недействительные SMILES-нотации. Бенчмарк-наборы данных следует тщательно проверять на корректность химических структур.
Единое химическое представление
Структуры химических соединений в бенчмарк-наборе данных должны быть стандартизированы согласно принятой конвенции. В случае с набором данных MoleculeNet это не так. Например, рассмотрим 59 бета-лактамных антибиотиков в наборе данных MoleculeNet для ГЭБ. В зависимости от структуры, карбоксильная группа в этих молекулах может быть представлена тремя различными способами: протонированной кислотой, анионным карбоксилатом и анионной солью. Мы должны сравнивать производительность молекулярных представлений и алгоритмов машинного обучения, а не методов стандартизации.
Стереохимия
При моделировании связи между химической структурой и каким-либо физическим свойством или биологической активностью, важно быть уверенным, что моделируется правильная структура. Кроме того, помимо структур, которые не могут быть разобраны, существуют более тонкие и сложные проблемы со структурой, с которыми мы должны иметь дело. Прежде всего, это стереохимия. Стереоизомеры могут иметь сильно разные свойства и биологическую активность. Рассмотрим набор данных BACE в MoleculeNet. В этом наборе данных есть 28 наборов стереоизомеров. В двух случаях у нас есть 3 стереоизомера, в остальных случаях — 2. Проблемы возникают, когда стереохимия неоднозначна. Например, 71% молекул в наборе BACE имеют хотя бы один неопределенный стереоцентр. Идеально, бенчмарк-наборы данных должны состоять из ахиральных или хирально чистых молекул с четко определенными стереоцентрами. Улучшение оценки методов машинного обучения проблематично. Так как сложно делать прогнозы, когда мы не знаем, о каких молекулах идет речь.
Согласованные измерения
Идеальным вариантом было бы, если бы эксперименты, используемые для создания бенчмарк-наборов данных, проводились в одной и той же лаборатории при одинаковых условиях. Если наборы данных собираются из нескольких лабораторий, следует использовать набор стандартов для обеспечения однородных результатов. К сожалению, это далеко не всегда так для большинства наборов данных в коллекции MoleculeNet. Например, широко используемый набор данных MoleculeNet для BACE был собран из 55 статей. Маловероятно, что авторы этих 55 статей использовали одни и те же экспериментальные методы для определения IC50.
Отчеты Грега Ландрума, опубликованные недавно в блоге, анализировали влияние объединения данных IC50 и Ki из разных анализов. Грег обнаружил, что объединение данных из анализов Ki иногда допустимо, но ситуация с данными IC50 была более сложной. Даже в лучших условиях 45% значений для одной и той же молекулы, измеренные в двух разных статьях, различались более чем на 0.3 логарифма, что считается типичной погрешностью эксперимента. В конечном итоге, если мы объединяем наборы данных, мы должны делать это осторожно.
Реалистичный динамический диапазон и пороги
Динамический диапазон данных, используемых в бенчмарках, должен тесно соответствовать диапазонам, с которыми мы имеем дело на практике. Это не так для набора данных о водной растворимости ESOL в MoleculeNet. Большинство фармацевтических соединений обычно имеют растворимость где-то между 1 и 500 µM. Анализы обычно проводятся в этом относительно узком диапазоне, охватывающем 2.5-3 логарифма. Значения менее 1 µM часто сообщаются как «<1 µM», а значения более 500 µM — как «>500 µM». Этот узкий динамический диапазон затрудняет достижение хороших корреляций между экспериментальными и прогнозируемыми значениями.
Улучшение оценки методов машинного обучения может помочь справиться с этой сложностью. С другой стороны, набор данных ESOL в MoleculeNet охватывает более 13 логарифмов, и с помощью очень простых моделей можно получить хорошую корреляцию. К сожалению, эта производительность не отражает того, что мы видим при прогнозировании реалистичных тестовых наборов данных. Для получения дополнительной информации см. этот недавний пост в блоге Practical Cheminformatics.
Также при оценке моделей классификации необходимо установить пороговое значение, определяющее границу между молекулами в одной категории и молекулами в другой. Например, рассмотрим набор данных BACE в MoleculeNet, который используется в качестве бенчмарка для классификации. Молекулы с значениями IC50 менее 200 нМ считаются активными, а молекулы с значениями IC50 больше или равно 200 нМ считаются неактивными. Выбор 200 нМ как порогового значения для активности выглядит странным. Это значительно более высокая активность, чем значения, которые обычно встречаются при просе, где значения IC50 обычно находятся в диапазоне одного до двух десятков микромолей. Порог также в 10-20 раз больше, чем IC50, который обычно нацеливается при оптимизации ведущих соединений. В конечном итоге классификационный бенчмарк BACE не кажется отражающим ситуацию, с которой мы сталкиваемся на практике.
Четкое определение наборов данных для обучения, валидации и тестирования
При создании модели машинного обучения важно разделить данные на наборы для обучения, (иногда) валидации и тестирования. Мы хотим избежать утечки информации из набора данных для обучения в набор данных для тестирования. Во многих статьях, не существует общепринятой конвенции разделения наборов данных. Некоторые группы используют случайное разделение, другие — разделение по скелету молекулы разного вида, а некоторые используют разделение на основе кластеров. Чтобы обеспечить согласованность, полезно было бы, чтобы каждый бенчмарк-набор данных включал метки, указывающие предпочтительное соотношение наборов данных для обучения, валидации и тестирования.
Ошибки при отборе данных
В некоторых случаях мы сталкиваемся с данными для бенчмарка, которые были некорректно сформированы. Например, рассмотрим широко используемый набор данных BBB в MoleculeNet. Несмотря на то что этот набор данных использовался в сотнях публикаций, никто, похоже, не обратил внимания на несколько серьезных ошибок. Во-первых, набор данных содержит 59 дублирующихся структур. Это не то, что мы хотим видеть в бенчмарке. Но давайте поднимем планку – 10 из этих дубликатных структур имеют разные метки. Да, набор данных BBB содержит 10 пар (см. ниже), где одна и та же молекула помечена как проникающая через гематоэнцефалический барьер (ГЭБ), так и не проникающая через ГЭБ. Есть и другие ошибки, например, глибурид помечен как проникающий в мозг, хотя литература утверждает обратное.
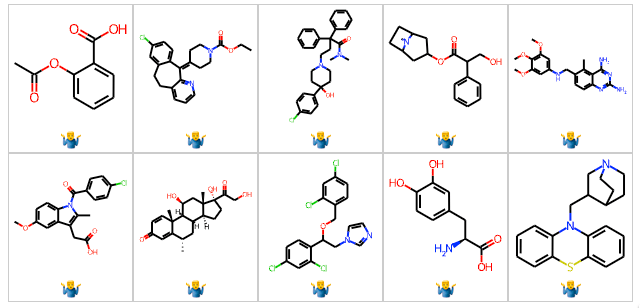
Понятно, что ошибки могут проникнуть в эти наборы данных. Во многих случаях люди просто объединяют таблицы данных из нескольких статей и называют это бенчмарк-набором данных. Нам нужно перейти к более системному подходу, при котором несколько групп будут оценивать бенчмарки и подтверждать их корректность.
Философские вопросы
Переходя от чисто технических аспектов, мы переходим к более философскому обсуждению характеристик, которые определяют хороший бенчмарк-набор данных.
Задачи, для которых используются бенчмарки, должны быть релевантными
Задачи бенчмарка должны быть релевантными для типичной работы, выполняемой в конкретной области, в данном случае, в области открытия лекарств. Множество статей сообщали и сравнивали результаты на наборе данных FreeSolv в MoleculeNet. Этот набор данных был разработан для оценки способности молекулярных динамических симуляций оценивать свободную энергию растворения, которая является существенной составляющей вычислений высвобожденной энергии. Однако эта величина сама по себе не является особо полезной.
Также набор данных MoleculeNet включает в себя наборы данных QM7, QM8 и QM9, изначально разработанные для оценки прогнозирования квантово-химических свойств на основе 3D-структур. Следует отметить, что большинство этих свойств зависят от 3D-координат атомов и будут изменяться с конформацией. Многие авторы сообщали и сравнивали прогнозы этих свойств на основе строк SMILES. Хотя некоторые утверждают, что 1D-представление, такое как SMILES, может включать в себя некоторые компоненты 3D-структуры, прогнозирование свойств одной конформации молекулы на основе SMILES не имеет особого смысла.
Избегать анализов с высоким количеством артефактов
Еще одним набором из коллекции MoleculeNet, на который часто ссылаются, является набор данных об HIV. Этот набор данных состоит из бинарных меток, полученных из 40 000 соединений, протестированных в клеточном анализе для выявления молекул, способных ингибировать репликацию ВИЧ. К сожалению, этот набор данных содержит много соединений, которые, вероятно, могут вызвать артефакты в анализе. Улучшение оценки методов машинного обучения позволило бы более точно выявить настоящие ответы. 70% молекул, помеченных как «подтвержденно активные», вызывают один или несколько структурных сигналов. Из 404 молекул, помеченных как подтвержденно активные, 68 — это азо-красители, широко известные своей цитотоксичностью и влиянием на анализ. Подробнее об этом наборе данных рассказывается в блоге Practical Cheminformatics в 2018 году. Если мы используем набор данных как бенчмарк, мы должны убедиться, что мы изучаем настоящий ответ, а не артефакт.
Сейчас сосредоточимся на простых, согласованных, четко определенных конечных точках
Одним из наиболее широко известных наборов данных MoleculeNet. Этот является набор данных о проникновении через гематоэнцефалический барьер (BBB). Этот набор данных содержит 2050 молекул с бинарной меткой, указывающей, проникает ли молекула через ГЭБ. Проникновение соединений в центральную нервную систему (ЦНС) — это сложный процесс. Молекулы могут транспортироваться активно или могут пройти один из нескольких параклетических путей через ГЭБ. Способность соединения проникнуть в ЦНС также может быть облегчена или затруднена некоторыми заболеваниями. Различные экспериментальные методы были применены для измерения проникновения в ЦНС. В некоторых случаях это основано на исследованиях на животных; в других случаях измерения проводятся на церебральной жидкости пациентов.
Многие авторы просто классифицируют любые препараты, используемые для психиатрических показаний. Или препараты с побочными эффектами, такими как сонливость, как проникающие через ЦНС. Также следует отметить, что экспериментальные измерения проникновения через ГЭБ значительно варьируются. В обзоре 2022 года, проведенном Хаддадом по вопросу проникновения антибиотиков в ЦНС. Процент Ceftriaxone в цереброспинальной жидкости относительно плазмы варьировал от 0,5 до 95%. Различия между свободной и белковой концентрацией в ЦНС дополнительно усложняют эту проблему. Хотя проникновение в ЦНС важно во многих терапевтических областях, неясно, что методы машинного обучения, обученные на недостоверных данных, существенно влияют на эту область. Возможно, мы могли бы получить больше пользы. Тщательно изучив конгенные серии, в которых некоторые соединения показали активность в ЦНС, а другие — нет. С точки зрения бенчмаркинга сложно сравнивать методы на основе высоковариабельного гетерогенного конечного пункта.
Наборы данных конечных точек
Рассматривая плохо определенные конечные точки, следует обсудить наборы данных, связанные с токсичностью, в MoleculeNet. В подразделе «Физиология» есть 4 таких набора данных.
SIDER
Коллекция из 1427 химических структур с сопутствующими побочными эффектами, разделенными на категории. Начиная от «Заболевания печени и желчевыводящих путей» и «Инфекции и наружные поражения» и заканчивая менее научными категориями. Такими как «Проблемы с продукта», «Исследования» и «Социальные обстоятельства». Учитывая неоднозначность и отсутствие механистической информации, связанной с побочными эффектами. Это кажется плохим выбором для бенчмарка.
Toxcast
Набор из 8595 химических структур с 620 конечными точками из высокопроизводительного скрининга с использованием панели клеточных анализов. Разработанных для оценки широкого спектра токсичности. Этот набор данных не является полной матрицей. Колонки анализов обычно имеют около 2500 двоичных меток и около 6000 пропущенных значений. Как можно было ожидать, в наборе данных есть много «плохих актеров». 56% молекул в наборе вызывают одно или несколько структурных предупреждений. Учитывая большое количество анализов, пропущенных значений и неопределенности, связанной с данными высокопроизводительного скрининга. Это кажется плохим выбором для бенчмарка. Большинство статей, сравнивающих результаты для этого набора данных, просто сообщают средний показатель площади под кривой ROC (AUROC) для 620 анализов. Такое сравнение не информативно и мало что демонстрирует в плане полезности модели машинного обучения.
Tox21
Этот набор данных подобен набору данных Toxcast, описанному выше. Он состоит из 8014 соединений. Протестированных в 12 разных квантитативных клеточных анализах для активности нуклеарных рецепторов и стрессовых ответов. Как и в случае с Toxcast, ответы являются двоичными. С 189 до 961 активного соединения на анализ. Здесь данные менее разрежены, чем в наборе данных Toxcast. С 575 до 2104 пропущенных значений на анализ. Из четырех наборов данных о токсичности этот имеет наивысшее качество данных. Тем не менее, множество осложнений, связанных с клеточными анализами, не делают его лучшим выбором для бенчмаркинга.
Clintox
Этот набор данных состоит из 1483 строк SMILES и двух двоичных меток, указывающих, является ли молекула одобренным FDA препаратом, и были ли зарегистрированы побочные эффекты. Соединения охватывают широкий диапазон — от антибиотиков до оксида цинка. Учитывая отсутствие конкретной информации и множество механизмов клинических наблюдений за токсичностью, это кажется плохим выбором для бенчмаркинга предиктивных моделей.
Проблемы наборов токсичности
Очевидно, что предсказание токсичности имеет важное значение. Мы хотим создавать безопасные препараты. За последние 40 лет фармацевтическая индустрия разработала широкий спектр витро и виво анализов для оценки безопасности кандидатов на лекарства. Вычислительные группы разработали методы для предсказания результатов этих анализов на основе химической структуры. Хотя зачастую возможно установить связи между химической структурой и четко определенной конечной точкой. Предсказание сложных, часто субъективных клинических результатов на основе химической структуры проблематично в лучшем случае. Это не означает, что необходимо остановить работу над предсказанием токсичности. Но наборы данных MoleculeNet Tox не являются наилучшими сравнительными бенчмарками.
В большинстве случаев бенчмарки стали упражнениями в самолюбовании. Авторы составляют таблицу, показывая, как их метод, выделенный жирным шрифтом, превосходит текущее состояние. Очень мало внимания уделяется тому, почему один метод превосходит другой. Или какой метод лучше выделяет определенные химические характеристики. Переход к более надежным и четко определенным бенчмаркам поможет нам раскроить, что делают наши модели. И позволит нам двигаться вперед как отрасль.
Следующие шаги улучшение оценки методов машинного обучения
До сих пор было много речи о том, что идет не так. Давайте сменим акцент на то, что мы можем сделать, чтобы улучшить ситуацию.
Каковы дальнейшие перспективы?
На этом этапе, надеюсь, что в статье выше приведены сильные аргументы. Публикация бенчмарков на основе MoleculeNet — не лучшая идея. Набор данных TDC страдает от многих тех же недостатков, что и MoleculeNet. И также является плохим инструментом для бенчмаркинга. Как нам двигаться дальше? Вот несколько идей.
Концентрация усилий
Сосредоточить усилия по бенчмаркингу на простых, надежных, актуальных, четко определенных конечных точках. Изначально можно использовать растворимость в воде. Проницаемость через мембрану, ин витро метаболическую стабильность и биохимические анализы. Эти конечные точки воспроизводимы, относительно недороги и могут обеспечить достаточно большие наборы данных. Пока мы не разработаем четкое понимание этих бенчмарков, следует избегать более сложных клеточных или инвиво конечных точек.
Работа с артефактами
Разработать четкое понимание артефактов анализов и ввести ортогональные измерения для выявления «плохих элементов». В начальной стадии это можно сделать с помощью панели опытных практиков. Но мы должны двигаться в сторону более объективных мер.
Экспериментальная релевантность
Обеспечить тем, чтобы химические структуры молекул в наборе данных четко представляли соединения, использованные в эксперименте. Сосредоточьтесь на экспериментах с ахиральными молекулами и молекулами с четко определенной стереохимией. Идеально было бы также иметь доказательства чистоты и идентичности соединений.
Источники данных
Зафиксировать и сохранить происхождение данных. Обеспечить наличие экспериментальных процедур и измерений ошибок эксперимента в сопровождении наборов данных. Предоставить данные, демонстрирующие воспроизводимость эталонных стандартов. Во-первых, экспериментальная воспроизводимость позволяет другим расширить наборы данных или предоставить дополнительные доказательства вариабельности эксперимента. Во-вторых, по мере того как мы создаем модели машинного обучения, нам необходимо четко понимать отношения между точностью модели и ошибкой эксперимента.
Корректное использование
Давайте используем бенчмарки, чтобы узнать, где наши методы работают, а где нет. Просто выделение результатов жирным шрифтом в таблице никому не помогает. Понятно, что некоторые люди могут не иметь научной подготовки для интерпретации данных анализов. Но это создает отличную возможность для сотрудничества с экспериментаторами.
Постоянное развитие
Разработка бенчмарка — это непрерывная деятельность. Как указал Питер Истман, один из авторов MoleculeNet, версия 1.0 бенчмарка, вероятно, не будет идеальной. С течением времени, по мере оценки бенчмарка, его следует обновлять и поддерживать. Надеюсь, что мы сможем достичь момента, когда бенчмарки можно будет версировать, добавлять новые данные. И сообщество сможет иметь больше уверенности в опубликованных результатах.
Откуда возьмем эти наборы данных?
На этом этапе большинство читателей, вероятно, начинают терять терпение и задают два вопроса.
- Просто скажите мне, какие наборы данных мне следует использовать для бенчмаркинга.
- Учитывая доктринерские требования выше, откуда мы возьмем эти наборы данных?
Отвечая на первый вопрос, на данный момент четких ответов. Один перспективный набор данных, представлен в недавней работе Чэн Фанга и его коллег из Biogen. В этой статье авторы предоставили большой набор данных о измерениях АДМЕ. Абсорбции, распределении, метаболизме и экскреции. Для коммерчески доступных соединений, подобных тем, что встречаются в программе поиска лекарств. Все структуры и данные доступны в машиночитаемом формате на GitHub.
Набор данных Biogen — это хороший старт, но нам нужно больше данных. Многие предлагали, чтобы фармацевтические компании открыли больше своих данных для сообщества. Было бы здорово увидеть больше усилий, подобных усилиям Biogen. Но здесь играют роль вопросы интеллектуальной собственности. Когда в дело вступают юристы, ничто не движется быстро. Кроме того, каждая компания проводит свои анализы по-разному, и объединение наборов данных будет сложной задачей.
Создание и финансирование общего проекта
Лучший способ достичь прогресса в области применения машинного обучения к поиску лекарств — это финансирование большого публичного проекта. Который создаст высококачественные данные и сделает их доступными для сообщества. Как отрасль, нам не нужна еще одна большая языковая модель. Которая будет производить инкрементально лучшие результаты на каком-то бессмысленном бенчмарке. Нам нужны актуальные, высококачественные наборы данных, которые мы можем использовать в качестве бенчмарков. Кроме того, нам следует тщательно оценить данные бенчмарка. Чтобы выявить преимущества и недостатки наших методов и разработать стратегии для преодоления ограничений.
За последние 10 лет наблюдается значительный рост применения методов машинного обучения для решения широкого спектра проблем в области поиска лекарств. Множество академических компьютерных групп вступили в эту область. И применили передовые методы глубокого обучения к задачам, связанным с жизнью. Несмотря на то что эти усилия имеют значительный шанс продвинуть область, отсутствие подходящих бенчмарков затрудняет определение того, идем ли мы вперед. Крайне негативно, что финансовые органы продолжают поддерживать исследования новых методов машинного обучения. Но не желают финансировать усилия по улучшение оценки методов машинного обучения и созданию данных. Которые можно было бы использовать для обучения и проверки моделей машинного обучения для поиска лекарств. Многое было сказано о потенциале моделей машинного обучения для трансформации здравоохранения. Но очень мало было сделано для создания данных, необходимых для этого. Усилия по созданию этих данных являются одним из самых важных вкладов. Который мы можем внести в человеческое здоровье.
Как уже сказано, нет на все ответов, но всем следует начать диалог.
Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.