
Благодаря своей обширной функциональности и универсальности, pandas завоевала место в сердце каждого специалиста data science. В этой статье мы посмотрим на новые функции в Pandas 2.0
Pandas — это библиотека Python для обработки и анализа структурированных данных, её название происходит от «panel data» («панельные данные»).
Панельными данными называют информацию, полученную в результате исследований и структурированную в виде таблиц. Для работы с такими массивами данных и создан Pandas.
От ввода / вывода данных до очистки и преобразования данных — практически невозможно представить себе работу с данными без import pandas as pd, верно?
Новые функции в Pandas 2.0
Создатели столь популярной библиотеки сложа руки не сидели, и вот 16 марта, после 3 лет разработки, был выпущен второй релиз pandas 2.0. В pandas 2.0 появилось много новых функций, включая улучшенную поддержку массивов расширений, поддержку pyarrow для фреймов данных и разрешение даты и времени, отличного от наносекундного, а также множество исправлений и, следовательно, изменений API.
Итак, что же революционного предлагает pandas 2.0?
1. Производительность, скорость и эффективность использования памяти
Изначально pandas был создан с использованием библиотеки numpy, которая намеренно не разрабатывалась в качестве серверной части для фреймворков данных. По этой причине одним из основных ограничений pandas была обработка больших наборов данных в памяти.
В этом релизе 2.0 большое изменение связано с внедрением серверной части Apache Arrow для данных pandas.
По сути, Arrow — это стандартизированный формат столбчатых данных в памяти с доступными библиотеками для нескольких языков программирования (C, C++, R, Python и других). Для Python есть PyArrow, который основан на реализации Arrow на C++ и, следовательно, очень быстр!
Суммируя, PyArrow заботится о предыдущих ограничениях памяти версий 1.X и позволяет выполнять более быстрые и экономичные с точки зрения памяти операции с данными, особенно для больших наборов данных.
Вот сравнение между чтением данных без серверной части pyarrow и с ее помощью, используя набор данных Hacker News, который составляет около 650 МБ (лицензия CC BY-NC-SA 4.0):
%timeit df = pd.read_csv("data/hn.csv")
# 12 s ± 304 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df_arrow = pd.read_csv("data/hn.csv", engine='pyarrow', dtype_backend='pyarrow')
# 329 ms ± 65 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)Как вы можете видеть, использование нового бэкенда ускоряет чтение данных почти в 35 раз! Другие аспекты, на которые стоит обратить внимание:
- Без серверной части
pyarrowкаждый столбец / объект хранится как свой уникальный тип данных: числовые объекты хранятся какint64илиfloat64, в то время как строковые значения хранятся как объекты. - В
yarrowвсе функции используют типы стрелок: обратите внимание на аннотацию [pyarrow] и различные типы данных:int64,float64,string,timestampиdouble:
df = pd.read_csv("data/hn.csv")
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 3885799 entries, 0 to 3885798
# Data columns (total 8 columns):
# # Column Dtype
# --- ------ -----
# 0 Object ID int64
# 1 Title object
# 2 Post Type object
# 3 Author object
# 4 Created At object
# 5 URL object
# 6 Points int64
# 7 Number of Comments float64
# dtypes: float64(1), int64(2), object(5)
# memory usage: 237.2+ MB
df_arrow = pd.read_csv("data/hn.csv", dtype_backend='pyarrow', engine='pyarrow')
df_arrow.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 3885799 entries, 0 to 3885798
# Data columns (total 8 columns):
# # Column Dtype
# --- ------ -----
# 0 Object ID int64[pyarrow]
# 1 Title string[pyarrow]
# 2 Post Type string[pyarrow]
# 3 Author string[pyarrow]
# 4 Created At timestamp[s][pyarrow]
# 5 URL string[pyarrow]
# 6 Points int64[pyarrow]
# 7 Number of Comments double[pyarrow]
# dtypes: double[pyarrow](1), int64[pyarrow](2), string[pyarrow](4), timestamp[s][pyarrow](1)
# memory usage: 660.2 MB2. Типы данных со стрелками и числовые индексы
Помимо чтения данных, что является простейшим случаем, вы можете ожидать дополнительных улучшений для ряда других операций, особенно тех, которые связаны со строковыми операциями, поскольку реализация типа данных string в pyarrow довольно эффективна:
%timeit df["Author"].str.startswith('phy')
# 851 ms ± 7.89 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df_arrow["Author"].str.startswith('phy')
# 27.9 ms ± 538 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)Фактически Arrow имеет больше (и лучшую поддержку) типов данных, чем numpy, которые необходимы вне научной (числовой) области: даты и время, длительность, двоичные числа, десятичные дроби, списки и карты.
Беглый просмотр эквивалентности между типами данных с поддержкой pyarrow и numpy на самом деле может быть хорошим упражнением, если вы хотите научиться их использовать.
Кроме того, теперь в индексах можно хранить больше numpy-числовых типов. Традиционные int64, uint64 и float64 освободили место для всех индексных значений числовых типов numpy, поэтому мы можем, например, вместо этого указать их 32-разрядную версию:
pd.Index([1, 2, 3])
# Index([1, 2, 3], dtype='int64')
pd.Index([1, 2, 3], dtype=np.int32)
# Index([1, 2, 3], dtype='int32')Это долгожданное изменение, поскольку индексы являются одной из наиболее часто используемых функций в pandas, позволяя пользователям фильтровать, объединять и перетасовывать данные, среди прочих операций с данными. По сути, чем меньше индекс, тем эффективнее будут эти процессы!
3. Упрощенная обработка пропущенных значений
Из-за того, что pandas был построен поверх numpy, ему было сложно обрабатывать отсутствующие значения простым и гибким способом, поскольку numpy не поддерживает значения null для некоторых типов данных.
Например, целые числа автоматически преобразуются в числа с плавающей запятой, что не идеально:
df = pd.read_csv("data/hn.csv")
points = df["Points"]
points.isna().sum()
# 0
points[0:5]
# 0 61
# 1 16
# 2 7
# 3 5
# 4 7
# Name: Points, dtype: int64
# Setting first position to None
points.iloc[0] = None
points[0:5]
# 0 NaN
# 1 16.0
# 2 7.0
# 3 5.0
# 4 7.0
# Name: Points, dtype: float64Обратите внимание, как points автоматически изменяется с int64 на float64 после введения единственного значения None.
Нет ничего худшего для потока данных, чем заданный неправильный тип, особенно в рамках подхода искусственного интеллекта, ориентированного целиком и полностью на данные.
Чем же это опасно?
Ошибочные наборы типов напрямую влияют на решения о подготовке данных, вызывают несовместимость между различными фрагментами данных, и даже при передаче в автоматическом режиме они могут поставить под угрозу определенные операции, которые в ответ выдают бессмысленные результаты.
В pandas 2.0 мы можем использовать dtype = 'numpy_nullable', где пропущенные значения учитываются без каких-либо изменений типа, поэтому мы можем сохранить наши исходные типы данных (в данном случае int64):
df_null = pd.read_csv("data/hn.csv", dtype_backend='numpy_nullable')
points_null = df_null["Points"]
points_null.isna().sum()
# 0
points_null[0:5]
# 0 61
# 1 16
# 2 7
# 3 5
# 4 7
# Name: Points, dtype: Int64
points_null.iloc[0] = None
points_null[0:5]
# 0 <NA>
# 1 16
# 2 7
# 3 5
# 4 7
# Name: Points, dtype: Int64Это может показаться незначительным изменением, но по правде, это означает, что теперь pandaspandas
4. Оптимизация копирования при записи
Pandas 2.0 также добавляет новый механизм отложенного копирования. Механизм откладывает копирование фреймов данных и объектов серии до тех пор, пока они не будут изменены.
Это означает, что определенные методы будут возвращать представления, а не копии, когда включена функция copy-on-write (копирования при записи), что повышает эффективность использования памяти за счет сведения к минимуму ненужного дублирования данных.
Это также означает, что вам нужно быть особенно осторожным при использовании цепных назначений.
Если включен режим copy-on-write, цепные присвоения работать не будут, поскольку они указывают на временный объект, являющийся результатом операции индексирования (который при копировании при записи ведет себя как копия).
Когда copy_on_write отключен, такие операции, как slice, могут изменить исходный df при изменении нового фрейма данных:
pd.options.mode.copy_on_write = False # disable copy-on-write (default in pandas 2.0)
df = pd.read_csv("data/hn.csv")
df.head()
# Throws a 'SettingWithCopy' warning
# SettingWithCopyWarning:
# A value is trying to be set on a copy of a slice from a DataFrame
df["Points"][0] = 2000
df.head() # <---- df changesКогда copy_on_writeChainedAssignmentError
pd.options.mode.copy_on_write = True
df = pd.read_csv("data/hn.csv")
df.head()
# Throws a ChainedAssignmentError
df["Points"][0] = 2000
# ChainedAssignmentError: A value is trying to be set on a copy of a DataFrame
# or Series through chained assignment. When using the Copy-on-Write mode,
# such chained assignment never works to update the original DataFrame
# or Series, because the intermediate object on which we are setting
# values always behaves as a copy.
# Try using '.loc[row_indexer, col_indexer] = value' instead,
# to perform the assignment in a single step.
df.head() # <---- df does not change5. Дополнительные зависимости
При использовании pip версия 2.0 дает нам гибкость в установке вспомогательных зависимостей, что является плюсом с точки зрения настройки и оптимизации ресурсов.
Мы можем адаптировать установку к нашим конкретным требованиям, не тратя дисковое пространство на то, что нам на самом деле не нужно.
Кроме того, это избавляет от многих «головных болей с зависимостями», снижая вероятность проблем с совместимостью или конфликтов с другими пакетами, которые могут возникнуть в наших средах разработки:
pip install "pandas[postgresql, aws, spss]>=2.0.0"Финальный аккорд…
Тем не менее остается вопрос: действительно ли шумиха оправдана? Было любопытно посмотреть, обеспечил ли pandas 2.0 значительные улучшения в отношении некоторых пакетов, которые многие разработчики используют ежедневно: ydata-profiling, matplotlib, seaborn, scikit-learn.
Исходя из этого, стоит попробовать ydata-профилирование — оно только что добавило поддержку pandas 2.0. В новой версии пользователи могут быть уверены, что их конвейеры не сломаются, если они используют pandas 2.0, и это большой плюс! Но что еще?
По правде говоря, профилирование ydata было одним из самых любимых инструментов многих специалистов для исследовательского анализа данных! С одной стороны, это всего лишь 1 строка кода, но под капотом полно вычислений, которые нужно выполнить — описательная статистика, построение гистограмм, анализ корреляций и так далее.
Итак, что может быть лучше, чем протестировать влияние движка pyarrow на все это сразу с минимальными усилиями?
import pandas as pd
from ydata_profiling import ProfileReport
# Using pandas 1.5.3 and ydata-profiling 4.2.0
%timeit df = pd.read_csv("data/hn.csv")
# 10.1 s ± 215 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit profile = ProfileReport(df, title="Pandas Profiling Report")
# 4.85 ms ± 77.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit profile.to_file("report.html")
# 18.5 ms ± 2.02 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# Using pandas 2.0.2 and ydata-profiling 4.3.1
%timeit df_arrow = pd.read_csv("data/hn.csv", engine='pyarrow')
# 3.27 s ± 38.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit profile_arrow = ProfileReport(df_arrow, title="Pandas Profiling Report")
# 5.24 ms ± 448 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit profile_arrow.to_file("report.html")
# 19 ms ± 1.87 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)Опять же, считывание данных определенно лучше с помощью движка yarrow, хотя создание профиля данных существенно не изменилось с точки зрения скорости.
Тем не менее различия могут зависеть от эффективности использования памяти, для чего пришлось бы провести другой анализ. Кроме того, можно дополнительно изучить тип анализа, проводимого над данными: для некоторых операций разница между версиями 1.5.2 и 2.0 кажется незначительной.
Но главное, что может иметь значение — это то, что ydata-profiling еще не использует типы данных pyarrow. Это обновление может оказать большое влияние как на скорость, так и на объем памяти, и мы с нетерпением ждем его в будущих разработках!
Резюме: Производительность, гибкость, интер-операбельность!
Эта новая версия pandas 2.0 обеспечивает большую гибкость и оптимизацию производительности благодаря тонким, но важным модификациям «под капотом».
Может быть они и не «кричащие» для новичков в области анализа данных. Но они словно вода в пустыне для опытных специалистов по обработке данных. Которые привыкли прыгать через горящие костры, чтобы преодолеть ограничения предыдущих версий.
Подводя итог, можно сказать, что это главные преимущества, представленные в новой версии:
- Оптимизация производительности: Благодаря внедрению серверной части Apache Arrow, большему количеству индексов
numpydtypeи режиму копирования при записи; - Дополнительная гибкость и настройка: Позволяет пользователям управлять необязательными зависимостями. И использовать преимущества типов данных Apache Arrow (включая возможность обнуления с самого начала!);
- Совместимость: возможно, это менее «признанное» преимущество новой версии, но имеющее огромное значение. Arrow не зависит от языка. Данные в памяти могут передаваться между программами, построенными не только на Python. Но также R, Spark и другими, использующими серверную часть Apache Arrow!
Pandas 2.0 предлагает множество новых и интересных функций. Надеюсь, что данная статья оказалась для вас полезной!
Новые функции в Pandas 2.0: Бонус!
Ура! Ты прочитал всю статью новые функции в Pandas 2.0 и теперь знаешь больше про новую версию библиотеки. Ниже полезные шаблоны по визуализации табличных данных.
import pandas as pd
import numpy as np
import matplotlib as mpl
df = pd.DataFrame({
"strings": ["Adam", "Mike"],
"ints": [1, 3],
"floats": [1.123, 1000.23]
})
df.style \
.format(precision=3, thousands=".", decimal=",") \
.format_index(str.upper, axis=1) \
.relabel_index(["row 1", "row 2"], axis=0)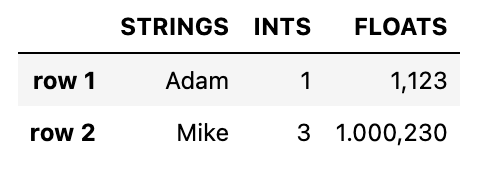
weather_df = pd.DataFrame(np.random.rand(10,2)*5,
index=pd.date_range(start="2021-01-01", periods=10),
columns=["Tokyo", "Beijing"])
def rain_condition(v):
if v < 1.75:
return "Dry"
elif v < 2.75:
return "Rain"
return "Heavy Rain"
def make_pretty(styler):
styler.set_caption("Weather Conditions")
styler.format(rain_condition)
styler.format_index(lambda v: v.strftime("%A"))
styler.background_gradient(axis=None, vmin=1, vmax=5, cmap="YlGnBu")
return styler
weather_df.loc["2021-01-04":"2021-01-08"].style.pipe(make_pretty)
Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.