В настоящее время MLOps (Machine Learning Operations) — популярная тема с множеством книг, статей, конференций и других ресурсов, посвященных созданию масштабируемого, повторяемого и готового к продакшн рабочего процесса машинного обучения. Несмотря на интерес, многоуровневая архитектура MLOps остается развивающейся областью, и существует множество различных подходов к реализации. Различия вызваны отсутствием единого мнения о том, как внедрить MLOps. В зависимости от ваших предпочтений, используемых технологий и задач, вам потребуется настроить подход к MLOps под требования вашей команды.
Сразу спойлер: если вы хотите быстро начать и стать более эффективными в своих проектах, можете сразу перейти к использованию шаблона Scaffolding Template, который обобщает подход этой статьи.
После работы с разными командами на разных уровнях зрелости в области машинного обучения, мы выявили общий паттерн: при подходе к новой задаче команды по анализу данных часто работают в две различные фазы, переход между которыми не всегда явный. Многие существующие подходы MLOps, с которыми многие сталкивались, учитывают это и поддерживают четкое разделение между фазами экспериментирования и развертывания в проекте по анализу данных; иногда это приводит к полному разделению кода для анализа данных и кода для развертывания.
Сначала у команды есть исследовательская фаза, в течение которой исследуются один или несколько подходов к моделированию; это обычно заканчивается выбором подхода для внедрения в продакшн или решением прекратить исследование. В этой фазе, в зависимости от зрелости команды в области машинного обучения, меньше внимания уделяется таким вопросам, как повторяемость и последовательность; мы часто наблюдаем, как участники команды работают в неформальных блокнотах Jupyter, используя среды conda, настроенные на их отдельной машине или вычислительных экземплярах. Здесь акцент сильно делается на наличии гибкой среды для попробовать новые идеи и быстро получить обратную связь о том, что работает, а что нет. Иногда это сопровождается подходом, который выражает следующее: Зачем тратить время на вопросы, такие как воспроизводимость, если работу можно будет отбросить?
Как только принимается решение внедрить решение в продакшн, наступает время задуматься о дополнительных аспектах, и появляются вопросы, такие как:
- Можем ли мы сделать процесс обучения более надежным и повторяемым?
- Как создать окружение таким образом, чтобы оно могло запускаться в любом месте?
- Как настроить автоматизированный процесс для запуска?
По нашему опыту, этот процесс может быть своего рода «большим взрывом», когда многое происходит одновременно, и результаты, а также взаимодействие аналитика данных с ними, могут значительно отличаться от предыдущего состояния. Этот процесс часто включает такие шаги, как миграция кода в новое место, определение общей среды выполнения процесса и добавление функций, таких как CI/CD-пайплайны для управления аспектами, такими как запуск развертываний и переобучение. Мы много раз наблюдали, что этот процесс «операционализации» внедрения может негативно повлиять на «внутренний обратный цикл» аналитика данных. Это означает, что, хотя рабочий процесс может быть изначально настроен на аналитика данных, дальнейший эксперимент может пострадать после смены этой концепции и может сделать итерации затруднительными.
Подытожим, что мы наблюдаем, что во многих случаях внедрение высокоавтоматизированных рабочих процессов MLOps, основанных на CI/CD, может оказаться сложным для аналитика. Несмотря на то, что повышается управляемость, масштабируемость и повторяемость, эти рабочие процессы могут негативно повлиять на быстрый обратный цикл, необходимый при исследовании новых идей, и нарушить итеративный опыт при проведении экспериментов. В худших случаях использование блокнотов и локального выполнения часто становятся второсортными, так как некоторые рабочие процессы требуют фиксации в git, запуска CI-пайплайнов и выполнения на удаленных кластерах, чтобы проверить даже небольшие изменения.
Кроме того, без предварительного рассмотрения переход от ручного запуска обучающих скриптов на локальной машине к запуску распределенных заданий в облаке (или в другом месте) может ввести множество дополнительных сложностей, таких как обеспечение согласованности среды, независимо от того, где выполняется эксперимент.

Наша философия
Наша цель заключается в том, чтобы определить подход к настройке проектов в области машинного обучения, который позволит нам:
- Минимизировать нарушения во время операционализации, поддерживая понимание непрерывного экспериментирования, чтобы несколько линий экспериментирования и развертывания могли сосуществовать, тем самым позволяя аналитикам данных продолжать итерировать и экспериментировать с быстрым обратным циклом независимо от этапа проекта.
- Структурировать наши проекты таким образом, чтобы вещи, которые принадлежат вместе, жили вместе. Это означает, что при взгляде на проект аналитик данных может быстро понять области, которые исследуются, сделав это прозрачным и легко определить все, что принадлежит той же линии работы. То есть код анализа данных (например, обучающие скрипты) должен находиться рядом с окружением выполнения, необходимым для его выполнения, и, если применимо, для развертывания результата.
- Выполнять код последовательно, независимо от того, исследуем ли мы идеи в блокноте Jupyter, запускаем ли скрипт на локальной машине или запускаем задание из облака.
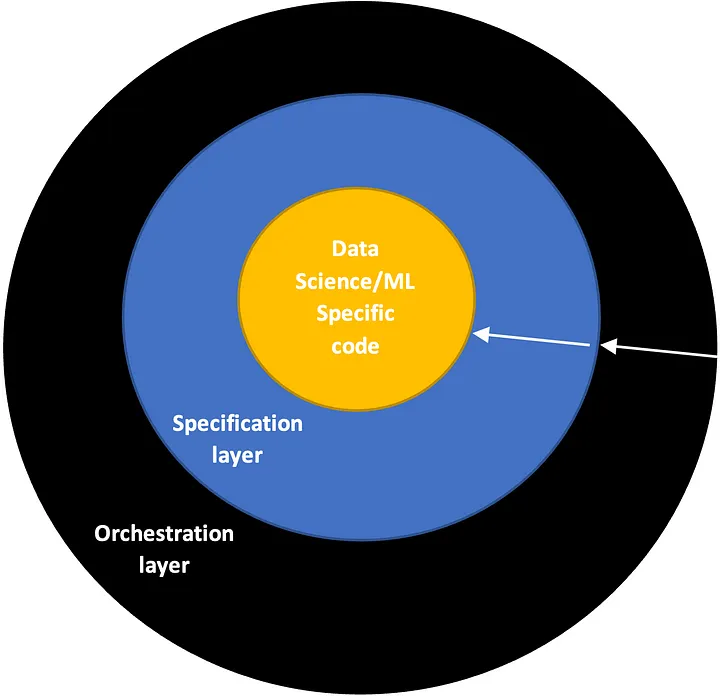
После множества экспериментов мы пришли к выводу о том, что лучше всего подходит метод визуализации наших проектов как последовательности концентрических слоев, где каждый слой может зависеть только от внутренних слоев, и каждый слой должен быть выполним сам по себе. В частности, слои, которые мы обычно рассматриваем, это:
- Слой data science: это ядро проекта. Он включает код, специфичный для задачи, которую мы пытаемся решить (например, обучение модели, предварительная обработка данных, оценка результатов и так далее). Он не должен зависеть от других слоев.
Примеры: обучающие скрипты на Python и связанные модули - Слой спецификации: этот слой включает все необходимые скрипты или файлы, которые определяют, как выполнять код анализа данных в среде выполнения. То есть, какой скрипт выполнять, в каком порядке, с какими параметрами, на какой вычислительной цели, под каким именем. Он должен зависеть только от слоя кода анализа данных.
Примеры: Dockerfile, команда AzureML для выполнения работы Yaml, шаблон рабочего процесса Argo (для Kubernetes) - Слой оркестрации: этот слой содержит логику, которая используется для запуска заданий и экспериментов, которые мы определили. Примером может служить код, который выполняет эксперимент по требованию или на основе событий (например, запуск еженедельного обучения). Это зависит от всех внутренних слоев.
Примеры: пайплайн CI Azure DevOps, рабочий процесс Github actions
Диаграмма концентрических слоев. Самый внутренний слой соответствует коду анализа данных, следующий — слой спецификации, а самый внешний — слой оркестрации.
Представление трех слоев. Стрелки представляют поток зависимостей.
Мы понимаем, что все это может показаться довольно абстрактным до данного момента. В следующих разделах мы пошагово разберем каждую концепцию и поэтапно представим пример, который наглядно демонстрирует, как можно применять эти принципы на практике. Реализация рабочего процесса, которую мы используем, была построена на основе введенных принципов и использована во многих наших проектах.
Превращаем теорию в практику
Теперь, когда мы очертили нашу философию на высоком уровне, давайте пошагово подойдем к реализации наших принципов. На каждом этапе мы постараемся детально описать наш выбор, и предоставить достаточно контекста, чтобы понять, как и почему это делается.
Здесь мы сфокусируемся на использовании Azure Machine Learning для выполнения и отслеживания экспериментов в облаке — это технология, которую мы обычно используем — но те же идеи могут быть применены к решениям от других поставщиков или к кластерам Kubernetes с Argo.
Готовый к использованию шаблон, демонстрирующий методологию, которую мы используем в этом разделе, можно найти здесь: Scaffolding Template. Целью шаблона является обеспечение возможности аналитикам данных быстро начать работу над своими проектами, предлагая простую и расширяемую стартовую точку.
Структурируем наш проект
Прежде чем мы начнем разговор о построении рабочего процесса, нам нужно что-то, над чем работать! Мы склонны думать о вещах в терминах задач, которые могут быть связаны с определенной областью. Следуя дизайну, ориентированному на область (DDD), мы считаем domain относящейся к реальной области или процессу, в рамках которого мы работаем. Некоторые примеры:
- Сегментация клиентов
- Распознавание цифр
- Поиск (для компании электронной коммерции)
Уровень детализации, на котором вы определяете область, в значительной степени зависит от среды, в которой вы работаете. Если вы часть команды с большим объемом задач, например, если вы отвечаете за весь поисковый движок, может иметь смысл определить области на высоком уровне — например, понимание запроса, построение запроса, повторная ранжировка результатов — а затем определить более конкретные подобласти для каждой области. В противном случае, если у вас очень узкая область ответственности, подобные подобласти могут не иметь смысла, и более конкретные задачи низкого уровня могут иметь больше смысла. Примеры задач включают в себя:
- Обучение модели ResNet50 для распознавания рукописных цифр
- Обработка сырых данных для создания подходящих обучающих и валидационных наборов
- Оценка результатов модели по определенным критериям
Важно, чтобы структура проекта отражала, хотя бы каким-то образом, реальную среду, в которой вы работаете, используя общий язык, который четко понимает вся команда.
Для примера давайте рассмотрим пример с распознаванем рукописных цифр, где нашей задачей является классификация каждой цифры в заранее определенную категорию. Поскольку эта область узкая, подобласти в значительной степени не требуются, и мы можем определить наши задачи как конкретные подходы, которые мы исследуем для решения этой проблемы. Например, мы могли бы структурировать наш проект следующим образом:
root
└── src
└── digit_recognition
├── random_svm_classifier
└── neural_net_classifierЗдесь мы создали папку для каждой линии экспериментирования, которую мы хотим исследовать в этой области. Поскольку у нас, вероятно, будет несколько областей, мы заключили это в родительскую папку src, чтобы сделать это легко расширяемым. Следуя введенным ранее принципам, мы должны стараться придерживаться следующих предположений:
- Все файлы, связанные с конкретной задачей, находятся вместе в соответствующей папке.
- Папки, соответствующие разным задачам, в значительной степени независимы друг от друга.
Следуя этим идеям, добавление или удаление задачи (или линии экспериментирования) не оказывает влияния на остальные. Таким же образом, развертывание результата одного из экспериментов отлично совместимо с продвижением других линий работы в том же проекте.
Однако, так как классификация цифр является относительно решенной проблемой на момент написания этого текста в конце 2022 года, давайте предположим, что выбранный нами подход сработает, и дополнительное исследование в этой области не требуется. Исходя из этого, мы можем упростить структуру следующим образом:
root
└── src
└── digit_recognitionЕще одно обстоятельство, о котором нам следует подумать, это вероятность того, что нам потребуется место для хранения данных на нашей машине при выполнении задач локально. Поскольку может быть, что несколько областей требуют те же данные, мы обычно сохраняем их в централизованной папке, не прямо связанной с каким-либо экспериментом. Структура становится следующей:
root
├── data
└── src
└── digit_recognitionМы, как правило, хотим избегать коммита данных в систему контроля версий (т. е. git), так как эти файлы обычно довольно большие и часто меняются, поэтому мы обычно игнорируем содержимое этой папки с помощью gitignore.
Слой data science: что это такое
Теперь, когда у нас есть базовая структура проекта, давайте рассмотрим самую интересную часть: код для data science, решающий нашу конкретную проблему и находящийся в ядре нашего проекта.
Несколько лучших практик:
- Должен существовать хотя бы один сценарий, который можно выполнить локально из командной строки и который отвечает за управление задачей. Хотя начальные исследования могут начинаться в блокнотах, их следует как можно скорее перенести в сценарий.
- Если требуется ряд шагов, компоненты которых настолько сложны, что они требуют несколько сценариев, единственным ручным взаимодействием, которое требуется, является выполнение каждого сценария в соответствующей последовательности и установка необходимых аргументов.
- Код в этом слое не должен зависеть от платформы, на которой мы собираемся его запускать (например, Azure, AWS и так далее).
Давайте создадим пример сценария обучения для нашей задачи распознавания цифр; то есть мы хотим обучить модель машинного обучения, которая может идентифицировать числа на картинках с одной написанной от руки цифрой. Поскольку это довольно просто с использованием современных библиотек, не требуются дополнительные пакеты или модули, и весь код для этого эксперимента в области науки о данных состоит всего лишь из следующего сценария, слегка измененной версии примера QuickStart из pytorch-accelerated:
# src/digit_recognition/train.py
import argparse
from torch import nn, optim
from torch.utils.data import random_split
from torchvision import transforms
from torchvision.datasets import MNIST
from pytorch_accelerated import Trainer
class MNISTModel(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.Linear(in_features=784, out_features=128),
nn.ReLU(),
nn.Linear(in_features=128, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=10),
)
def forward(self, input):
return self.main(input.view(input.shape[0], -1))
def train(epochs: int, batch_size: int, data_path: str):
dataset = MNIST(data_path, download=True, transform=transforms.ToTensor())
datasets = random_split(dataset, [50000, 5000, 5000])
train_dataset, validation_dataset, test_dataset = datasets
model = MNISTModel()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
loss_func = nn.CrossEntropyLoss()
trainer = Trainer(
model,
loss_func=loss_func,
optimizer=optimizer,
)
trainer.train(
train_dataset=train_dataset,
eval_dataset=validation_dataset,
num_epochs=epochs,
per_device_batch_size=batch_size,
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--epochs", type=int, help="Epochs to train for")
parser.add_argument("--batch_size", type=int, help="Batch size to train")
parser.add_argument("--data_path", type=str, help="Path where data is")
args = parser.parse_args()
train(args.epochs, args.batch_size, args.data_path)Мы можем поместить этот сценарий внутрь ранее определенной папки и назвать его train.py:
root
├── data
└── src
└── digit_recognition
└── train.pyТеперь мы готовы выполнить наш сценарий. Как видите, он не зависит от внешних платформ и, если все необходимые зависимости установлены в вашей локальной среде, может быть легко выполнен локально с помощью следующей команды (с условием, что ваша командная строка находится в корне вашего проекта для всех команд в этой статье):
python src/digit_recognition/train.py \
--epochs 8 --batch_size 32 --data_path "./data"Теперь перейдем к слою спецификаций!
Слой спецификаций: как это делается
После определения кода для науки о данных нам нужно определить следующий слой. Слой спецификаций содержит все детали, определяющие, как выполняется наш код для науки о данных на целевой платформе (например, облачная платформа). Хотя конкретные детали зависят от платформы, обязанности этого слоя включают:
- Указание значений аргументов и путей к источникам данных, необходимым для выполнения кода для науки о данных.
- Определение среды, в которой должен выполняться код.
- Определение последовательности выполнения шагов, обработка входных и выходных данных в соответствии с необходимостью.
- Предоставление интерфейса для любых аргументов, которые могут быть установлены для настройки выполнения задачи. Примером может быть выбор целевого вычислительного ресурса.
Давайте начнем с пожалуй, самого важного шага — окружающей среды выполнения.
Определение нашей среды выполнения
Хотя наш сценарий обучения не привязан к какой-либо конкретной платформе, у него есть зависимости от внешних пакетов. Если мы хотим, чтобы это было воспроизводимо, нам нужен способ управлять этими зависимостями!
Для целей этого примера мы начали с кода для науки о данных, но в реальности определение среды скорее всего будет происходить одновременно; поскольку мы обычно не знаем все зависимости, которые нам понадобятся заранее, создание среды может быть итеративным процессом!
Хотя существуют различные решения на языке Python для управления средой и зависимостями, после многих экспериментов — и многих часов, проведенных на отладке — мы обнаружили, что даже если участники команды используют одну и ту же среду, небольшие различия в условиях, таких как основная операционная система, могут привести к проблемам, которые очень трудно диагностировать. Это усложняется, когда мы начинаем выполнять код в нескольких местах, например, используя виртуальные машины в облаке!

Поэтому для того чтобы сделать нашу среду как можно более универсальной, рекомендуется использовать Docker. Вот некоторые аргументы:
- Полная воспроизводимость: контейнеры Docker обеспечивают не только одинаковые зависимости Python, но и одинаковую операционную систему и библиотеки. В проектах, где часто нужно использовать драйверы GPU, это крайне полезно.
- Крайне быстрая настройка: независимо от того, какую машину вы используете, вы устанавливаете Docker, создаете образ и готовы к запуску кода за несколько минут.
- Облачно дружественный: большинство (если не все) поставщики предоставляют образы Docker в качестве среды, в которой можно запустить наш код. Это делает крайне легким запуск кода локально таким же образом, как он будет работать в любом другом месте.
Это может показаться сложным для новичков, но преимущества перевешивают трудности обучения. Даже с базовыми знаниями можно достичь значительных результатов. Для новичков есть отличная статья: «Как Docker помогает повысить эффективность в проектах Data Science».
Мы можем определить наши образы Docker, создав Dockerfile, и мы предпочитаем делать их как можно проще. Например, Dockerfile, который нам нужен для запуска вышеуказанного кода, может выглядеть так:
FROM pytorch/pytorch:1.12.1-cuda11.3-cudnn8-runtime
RUN pip install 'pytorch-accelerated==0.1.35'Здесь мы берем официальный образ PyTorch, который также содержит torchvision и все необходимые нам драйверы CUDA, и устанавливаем любые другие пакеты, которые нам нужны сверху; здесь единственный пакет, который нам нужен, — это pytorch-accelerated. Как видно, мы не копируем наш сценарий обучения внутрь образа во время сборки. Хотя это был бы правильный подход, мы предпочитаем монтировать наш код во время выполнения, чтобы у нас всегда была самая последняя версия и не было необходимости пересобирать его каждый раз, когда мы вносим изменения.
Мы настоятельно рекомендуем создавать Dockerfile как можно скорее при начале новой задачи — даже создание минимальной среды перед началом исследования! Мы считаем, что это помогает поддерживать порядок с самого начала и делает действительно легким обмен кодом между командами!
Поскольку среда, определенная этим Dockerfile, специфична для нашей задачи digit_recognition, мы хотели бы держать ее как можно ближе к коду. Для ясности и удобства поместим его внутрь папки environment внутри нашего эксперимента. Наша структура теперь выглядит так:
root
├── data
└── src
└── digit_recognition
└── environment
│ └── Dockerfile
└── train.pyНекоторые облачные поставщики (включая Azure ML) могут кэшировать контекст Docker (т. е. файлы, которые находятся в той же папке, что и Dockerfile), чтобы пересобирать только образ (что может занять несколько минут), когда контекст изменяется. Разместив Dockerfile в своей собственной папке, мы убеждаемся, что мы перестраиваем только при изменении самого файла.
На этом этапе вы можете подумать: «Каким образом я использую это для запуска своего кода?» Поскольку мы интересуемся только определением наших ресурсов в слое спецификаций, мы перейдем к этому как часть следующего слоя — слоя оркестрации.
Определение задачи для запуска в облаке
Теперь, когда мы понимаем, как запустить наш сценарий локально, давайте рассмотрим, как создать определение задачи для запуска его в облаке. Детали здесь могут варьироваться в зависимости от используемой вами облачной службы, но общая идея определения некоего файла спецификации — который затем отправляется в выбранную вами службу — довольно стандартна. Здесь мы будем работать с Azure Machine Learning, которую мы используем в большинстве наших проектов, но подобный подход можно применить и при использовании других платформ; например, при выполнении на Kubernetes мы могли бы использовать шаблон Argo для этой цели.
Хотя не обязательно следовать здесь шаг за шагом, для получения дополнительной информации о начале работы с Azure ML мы рекомендуем посмотреть QuickStart из официальной документации или блог-пост Effortless distributed training for PyTorch models with Azure Machine Learning. Несмотря на то, что у AzureML есть Python SDK, мы настоятельно рекомендуем использовать Azure ML CLI (Command Line Interface), так как она позволяет вам указывать вещи декларативно в файлах YAML, вместо того чтобы писать Python-код. Это, по нашему мнению, делает намерения яснее, улучшает разделение обязанностей и уменьшает загромождение среды пакетами, не имеющими отношения к коду для науки о данных, который нас интересует.
Давайте определим команду Azure ML для выполнения нашего эксперимента в Azure ML. Поскольку наша цель здесь — не демонстрировать функции AzureML, главное, что следует помнить, — это то, что определение задачи — это файл YAML, в котором указываются:
- Название задачи для отображения в пользовательском интерфейсе мониторинга.
- Скрипт для запуска.
- Аргументы для использования.
- Среда, в которой должен выполняться код (контейнер Docker).
- Виртуальная машина, на которой мы хотим запустить задачу.
Более подробное руководство по задачам Azure ML и их выполнению с использованием CLI можно найти в вышеупомянутом QuickStart.
Мы можем определить это следующим образом:
# src/digit_recognition/azure-ml-job.yaml
# Tells Azure ML what kind of YAML this is.
# Docs: https://docs.microsoft.com/en-us/azure/machine-learning/reference-yaml-job-command
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# Name of the experiment where all jobs will end up in the Azure ML dashboard
experiment_name: digit_recognition
# What to run
command: >-
python train.py
--data_path ${{inputs.data_path}}
--epochs ${{inputs.epochs}}
--batch_size ${{inputs.batch_size}}
inputs:
data_path:
# Only works if dataset created using Azure ML CLI v2;
# run `az ml data create --help` to see how
path: azureml:mnist:1
epochs: 8
batch_size: 32
# What code to make available
code: .
# Where to run it (compute created beforehand).
environment:
build:
path: ./environment
compute: azureml:gpu-clusterОпять же, так как это специфично для нашей текущей задачи распознавания цифр, давайте разместим это рядом с нашим сценарием обучения, чтобы это было понятно. Таким образом, на данный момент наша структура файлов выглядит так:
root
├── data
└── src
└── digit_recognition
└── environment
│ └── Dockerfile
├── azure-ml-job.yaml
└── train.pyТеперь, когда мы определили детали того, как выполнить нашу задачу с использованием AzureML, давайте посмотрим, как мы можем ее запустить! Помним логические уровни, представленные ранее, это ответственность слоя оркестрации.
Слой оркестрации: когда это делать
До сих пор мы написали код для науки о данных, определили среду и указали, как его можно выполнить в облаке — теперь нам осталось только запустить его на самом деле! Этим занимается последний и самый внешний слой, который мы называем слоем оркестрации.
Слой оркестрации обычно содержит одного или несколько оркестраторов, которые представляют собой процессы, содержащие логику для запуска кода. Эти оркестраторы могут быть основанными на времени (например, запуск обучения каждый понедельник), данными (например, запуск предварительной обработки каждый раз при появлении новых данных) или управляемые вручную (например, кто-то нажимает кнопку где-то). Помним структуру зависимостей между нашими слоями, оркестраторы должны быть независимыми друг от друга и взаимодействовать только с внутренними слоями; это позволяет легко добавлять и удалять оркестраторы по мере необходимости!
Рассмотрим несколько примеров определения оркестраторов.
Создание локального оркестратора
Сначала мы хотим запустить код локально на нашей рабочей машине — будь то физический ноутбук или удаленная виртуальная машина — так как это обычно самый быстрый обратный путь для получения обратной связи. Давайте сначала рассмотрим шаги, которые нам нужно предпринять, чтобы использовать наш Dockerfile для запуска кода, прежде чем изучить, как мы можем реализовать локальный оркестратор, чтобы облегчить себе жизнь!
Запуск локально с использованием Dockerfile
Если вы не знакомы с Docker, некоторые из этих команд могут показаться сложными на первый взгляд, но не позволяйте этому вас отпугивать! Как показано ниже, все эти команды и даже больше — такие как запуск сервера Jupyter notebook непосредственно из образа Docker — могут быть четко абстрагированы нашим слоем оркестрации, чтобы нам не пришлось взаимодействовать с ними напрямую; не стесняйтесь пролистать эту часть, если вас не интересуют детали.
Прежде чем мы сможем что-либо запустить, нам нужно создать образ, который мы определили в нашем файле. Мы можем сделать это, запустив следующую команду. Хотя мы могли бы дать этому образу любое имя, давайте использовать имя нашего эксперимента для ясности:
docker build --tag digit_recognition ./src/digit_recognition/environmentТеперь, когда мы создали образ, мы можем использовать его для запуска нашего сценария обучения. Помним, что мы не включили наш код внутрь образа, нам нужно явно примонтировать эту папку — а также нашу папку с данными — чтобы мы могли получить к ней доступ внутри нашего работающего контейнера. Мы можем сделать это, используя следующую команду:
docker run --rm \
--mount type=bind,source="$(PWD)/data",target=/mnt/data
--mount type=bind,source="$(PWD)/src/digit_recognition",target=/mnt/digit_recognition \
--workdir /mnt \
digit_recognition:latest \
python digit_recognition/train.py --epochs 8 --batch_size 32 --data_path "./data"Однако, поскольку мы хотим, чтобы наш сценарий выполнялся на GPU, мы можем добавить несколько дополнительных аргументов, чтобы сделать это возможным, как показано ниже:
docker run --rm \
--gpus all --ipc host
--mount type=bind,source="$(PWD)/data",target=/mnt/data
--mount type=bind,source="$(PWD)/src/digit_recognition",target=/mnt/digit_recognition \
--workdir /mnt \
digit_recognition:latest \
python digit_recognition/train.py --epochs 8 --batch_size 32 --data_path "./data"Как видно, эти команды довольно длинные, и есть несколько сложностей, о которых нам нужно помнить! Давайте абстрагируем их за оркестратором.
Реализация локального оркестратора
Чтобы избежать необходимости запоминать довольно сложные команды, представленные выше, давайте создадим локальный оркестратор, который может служить абстракцией для нас при взаимодействии с кодом на нашей рабочей машине.
Существует множество технологий, которые мы могли бы использовать для реализации этого — таких как bash, Zsh или Windows Powershell, например — после многих экспериментов мы предпочитаем использовать Makefile, выполняемый с помощью GNU Make (по умолчанию установлен на большинстве UNIX-машин: Linux, macOS и WSL для Windows). Это не традиционное использование Makefile, мы находим, что это обеспечивает хороший компромисс между возможностью определения легко запоминаемых псевдонимов для сложных команд и при этом остается абсолютно прозрачным для тех, кто заинтересован в том, что происходит за кулисами!
Хотя детали написания Makefile в большей степени выходят за рамки этой статьи, мы можем абстрагировать наши предыдущие команды следующим образом:

Разместив этот файл в нашем корневом каталоге, мы можем запустить наш сценарий, используя следующую команду:
make local \
exp=digit_recognition \
script=train.py \
run-xargs="--gpus all" \
script-xargs="--epochs 8 --batch_size 32 --data_path './data'"Здесь Makefile гарантирует, что образ Docker эксперимента обновлен, и все необходимые файлы смонтированы в нужных местах, в то время как нам нужно помнить только простую команду. Обратите внимание, что избыточность этой команды в основном обусловлена script-xargs, что можно решить, создав файл local.py, который вызывает функцию в train.py с некоторыми параметрами по умолчанию.
Хотя реализация Makefile может показаться сложной для тех, кто не знаком с синтаксисом, к счастью, эти команды являются относительно общими и редко требуют изменений. В рамках нашего стартового шаблона мы предоставляем предопределенный Makefile, который часто не требует существенных изменений в основной функциональности в ходе наших проектов. Давайте скопируем его, папку с документами (которая содержит текст для справки, которую мы видим ниже), и конфигурационный файл для определения некоторых ключевых переменных среды в корень нашего репозитория. После этого наша структура каталогов выглядит следующим образом:
root
├── config.env
├── data
├── docs
├── Makefile
└── src
└── digit_recognition
└── environment
│ └── Dockerfile
├── azure-ml-job.yaml
└── train.pyИспользуем наш локальный оркестратор
Теперь, когда мы скачали предопределенные Makefile и файлы конфигурации из шаблона, настроим переменные config.env, как объяснено в репозитории.
Чтобы узнать доступные команды, просто запустим make help:
> make help
For a more detailed help of a command, run 'make help cmd=<cmd>'.
Commands:
build-exp : Builds experiment environment Docker image.
dependency : Make common dependency available in an experiment.
format : Format using black & isort. Display flake8 errors.
help : Show this help. Call `make help cmd=<cmd>` for detailed help.
job : Triggers Azure ML job for experiment.
jupyter : Spins jupyter lab inside Docker environment for experiment.
local : Executes python file inside Docker environment for experiment.
new-exp : Create new experiment folder from template.
terminal : Spins interactive terminal inside Docker environment for experiment.
test : Runs pytest inside Docker environment for experiment.Как видим, это выводит список всех доступных команд, включая опции для создания нового эксперимента, запуска сессии Jupyter notebook и отправки задач в облако, в дополнение к уже рассмотренным командам. Чтобы узнать больше о конкретной команде, можем использовать make help cmd=local:
> make help cmd=local
Command:
local : Executes python file inside Docker environment for experiment.
It is called `local` referencing that it runs in the host machine where the command is
called from and not in the cloud. By default, the script ran is `local.py`, which is what
comes predefined. This command makes sure all code (and only) for the experiment is
available in the same way it is when submitted to Azure ML through the `job` command.
This is the recommended way of executing scripts in this project for testing purposes,
as it makes sure the environment matches the one the experiment uses everywhere.
Arguments:
exp [Required] : Name of the experiment for which to run script; it is defined by the folder
name containing the experiment.
script : (Default local.py) Python file to run. It must be inside the experiment
folder. If not at root level of experiment, the full path from the experiment
root level has to be passed.
run-xargs : Extra arguments to be passed to the `docker run` command. It must be a
single string.
script-xargs : Extra arguments to be passed to the script. It must be a single string.
Examples:
Run default local.py without extra configuration
make local exp=example_experiment
Run custom file that requires an extra input and allow use of GPUs
make local exp=example_experiment run-xargs="--gpus all" script-xargs="--greeting Welcome"Это предоставляет более подробную информацию, такую как используемые аргументы.
Рассмотрим некоторые из команд, которые мы считаем наиболее полезными.
Отправляем наши эксперименты в Azure Machine Learning
Запустите команду make help cmd=job:
> make help cmd=job
Command:
job : Triggers Azure ML job for experiment.
This uses (and requires) to have the Azure ML CLI v2 installed. The job specs used are
the ones defined in `azure-ml-job.yaml` inside the experiment folder. Note that while
a command job is specified by default, you can use any type of job compatible with
Azure ML, you just need to change the YAML contents. For more information,
visit https://docs.microsoft.com/en-us/azure/machine-learning/reference-yaml-overview#job
Arguments:
exp [Required] : Name of the experiment for which to trigger the job; it is defined by the
folder name containing the experiment.
file : (Default azure-ml-job.yaml) YAML file with the specification of the job.
It must be inside the experiment folder. If not at root level of experiment,
the full path from the experiment root level has to be passed.
job-xargs : Optional extra arguments to be passed to the `az ml job create` call. It
should be a single string.
Examples:
Trigger a job in Azure ML without any extra configuration
make job exp=example_experiment
Trigger a job in Azure ML modifying one input using the extra configuration
make job exp=example_experiment job-xargs="--set inputs.greeting=Welcome"Предполагая, что AzureML CLI установлен, мы можем использовать его для запуска нашей задачи распознавания цифр в облаке, как показано ниже:
make job exp=digit_recognitionИзучение определения в Makefile:
job: file=azure-ml-job.yaml
job: check-arg-exp check-exp-exists
# Submit the job to Azure ML and continue to next step even if submission fails
az ml job create -f $(CODE_PATH)/$(exp)/$(file) \
--resource-group $(RESOURCE_GROUP) \
--workspace-name $(WORKSPACE) $(job-xargs) || trueЗдесь мы видим, что это всего лишь тонкая обертка вокруг команды AzureML, с некоторой дополнительной проверкой аргументов. Это запускает задачу в Azure ML на основе файла YAML, определенного в слое спецификации (то есть azure-ml-job.yaml), который, в свою очередь, вызывает код нашего слоя науки о данных (то есть train.py). Как видим, зависимости направлены только внутрь; код науки о данных независим от Azure ML, и спецификация задачи независима от того, когда или что вызывает фактическую отправку эксперимента.
Обработка общих зависимостей
До сих пор мы предполагали, что каждая задача, над которой мы работаем, полностью независима от других. Хотя это было бы идеальным случаем, мы часто обнаруживаем, что нам нужно повторно использовать функционал в разных экспериментах, особенно в рамках одной и той же области. С текущей структурой это было бы невозможно без дублирования файлов — что мы определенно хотим избежать.
Обычно принятым решением для обмена кодом между независимыми местами было бы упаковать такой код во внешний пакет. Хотя это, возможно, «лучший практический» вариант, это вносит много дополнительной сложности. Например, код должен быть перенесен в устанавливаемый пакет и — предполагая, что это закрытый, собственный код — размещен в частном репозитории пакетов. Дополнительные настройки требуются для управления секретами и обеспечения доступности этих частных пакетов в контексте сборки Docker. Хотя это, возможно, не проблема для опытной команды, мы часто считаем, что это чрезмерно для небольшой команды науки о данных, которая хочет поделиться всего лишь несколькими пакетами.
Наш подход к этому заключается в определении common каталога внутри нашего каталога src, чтобы было ясно, что код в этом каталоге может быть доступен для нескольких экспериментов.
root
├── config.env
├── data
├── docs
├── Makefile
└── src
├── common
└── digit_recognition
└── environment
│ └── Dockerfile
├── azure-ml-job.yaml
└── train.pyПосле того как это определено, мы можем выбирать конкретный код, к которому хотим получить доступ для конкретного эксперимента, используя команду make dependency. Снова может быть полезна справка:
> make help cmd=dependency
Command:
dependency : Make common dependency available in an experiment.
This makes a common dependency living in the `common` folder at experiment level
available inside the `common` folder of the specified experiment. That way, that
dependency can be used in the experiment that now have it. For consistency, this command
introduces the dependency in the experiment within the same original folder structure.
That is, the path to the dependency is the same in all `common` folders that contain it.
As a technical detail, we use symlinks for this functionality. This means that any change
will be reflected in all references of the file or folder.
Arguments:
exp [Required] : Name of the experiment in which we want to make the dependency available;
it is defined by the folder name containing the experiment.
dep [Required] : Path to the dependency inside the original common folder. A dependency can
either be a file or a folder. `common` should not be included in the path
provided, as the command already accounts for it.
Examples:
Introduce dependency to `printer.py` in the `example_experiment` so it can be used.
make dependency exp=example_experiment dep=printer.pyЗа кулисами основной функционал основан на символических ссылках (эквивалент прямых доступов в Windows, но для UNIX-систем). Таким образом, мы можем сохранить единственную исходную версию кода, но можем импортировать общие компоненты внутри каждого эксперимента так, как если бы они находились в одном и том же каталоге. Команда local монтирует папки таким образом, что это работает. К тому же символические ссылки также уважаются AzureML при отправке задач в облако, что делает это надежным решением для запуска как локально, так и в облаке!
Запуск сессии Jupyter Notebook
Запуск команды make help cmd=jupyter:
> make help cmd=jupyter
Command:
jupyter : Spins jupyter lab inside Docker environment for experiment.
It uses the image created in `build-exp` command for the same experiment. This command
makes sure all code (and only) for the experiment is available in the same way it is
when submitted to Azure ML through the `job` command. Additionally, the notebooks folder
is also mounted. This is the recommended way of working with jupyter in this project, as
it ensures the environment matches the one the experiment uses everywhere.
Arguments:
exp [Required] : Name of the experiment for which to spin jupyter; it is defined by the
folder name containing the experiment.
port : (Default 8888) Port where jupyter runs and is exposed.
run-xargs : Extra arguments to be passed to the `docker run` command. It must be a
single string.
Examples:
Spin up the default jupyter lab without any extra configuration
make jupyter exp=example_experiment
Spin up jupyter lab exposed in a different port (useful when host machine is already using
the port, like Azure ML compute instances) and allowing the use of GPUs.
make jupyter exp=example_experiment port=8890 run-xargs="--gpus all"Здесь у нас есть возможность запустить сервер JupyterLab внутри Docker-среды, определенной для нашего эксперимента. Мы можем выполнять Jupyter-блокноты, неотъемлемый инструмент в мире науки о данных, в той же среде, что и все остальное, связанное с задачей.
Так как мы обычно советуем использовать блокноты только для ад-хок исследований и как можно скорее переходить к скриптам. Советуем держать блокноты отдельно от общего кода, подчеркивая четкое разделение между исследовательской работой и скриптами, которые могут быть операционализированы. Создадим папку на уровне корня, которую можно использовать для хранения наших блокнотов.
root
├── config.env
├── data
├── docs
├── notebooks
├── Makefile
└── src
├── common
└── digit_recognition
└── environment
│ └── Dockerfile
├── azure-ml-job.yaml
└── train.pyТеперь запустим наш сервер Jupyter, выполнив следующую команду:
make jupyter exp=digit_recognitionЭта команда заботится о необходимой пересылке портов, позволяя нам получить доступ к серверу Jupyter (работающему внутри Docker-контейнера) из браузера:
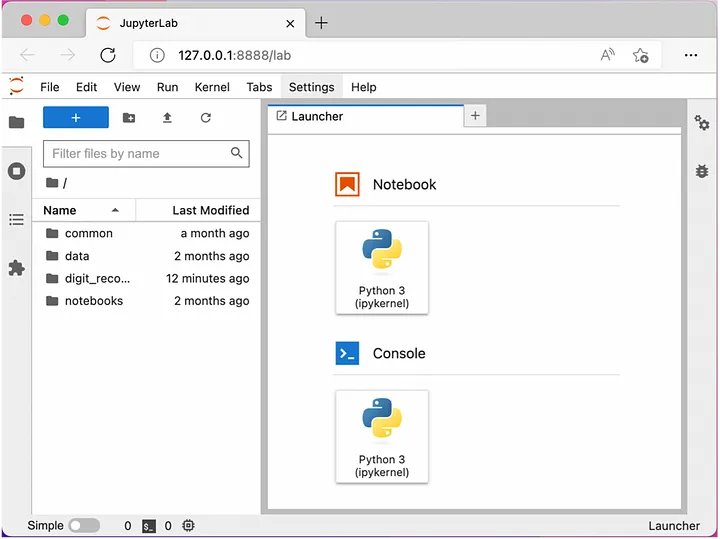
Здесь мы видим, что весь наш код доступен нам — включая любые связанные общие зависимости (если у нас были бы) — а также наши блокноты и папки с данными, что должно быть все, что нам нужно для экспериментов!
Создание оркестратора на основе CI
Несмотря на то что мы много времени потратили на изучение того, как использовать наш локальный оркестратор, мы часто хотим иметь возможность выполнения задач из рабочих процессов CI, которые могут быть запущены при различных событиях. Поэтому, помимо нашего Makefile, мы часто создаем оркестраторы с использованием технологий, таких как Github Actions или конвейеры Azure DevOps. В отличие от Makefile, это касается обычно папки orchestration на уровне корня, которые независимы от всех экспериментов.
root
├── config.env
├── data
├── docs
├── notebooks
├── orchestration
├── Makefile
└── src
├── common
└── digit_recognition
└── environment
│ └── Dockerfile
├── azure-ml-job.yaml
└── train.pyПомимо того, что это облегчает добавление и удаление оркестраторов, это предоставляет нам гибкость создавать оркестрационные конвейеры, которые могут запускать несколько задач как часть большего рабочего процесса.
Ниже мы видим упрощенный пример того, как мы могли бы создать CI-триггер для нашей задачи распознавания цифр, используя конвейер Azure DevOps. Здесь не важны детали; ключевое наблюдение заключается в том, что этот оркестратор взаимодействует только с файлом YAML AzureML, определенным в слое спецификации.
schedules:
- cron: "0 3 * * Mon"
displayName: Monday 3:00 AM (UTC) weekly retraining
branches:
include:
- /releases/lastversion
always: true
parameters:
- name: azure_cli_version
type: string
default: 2.7.1
- name: epochs
type: number
default: 10
values:
- 1
- 10
variables:
- template: ../config/ado-pipelines-variables.yaml
- group: subscription-secrets
- name: scriptRoot
value: src/digit_recognition
jobs:
- job: Train_Digit_Classifier
displayName: Digit Recognition
steps:
- template: ../templates/install-azureml-cli.yaml
parameters:
cli_version: ${{ parameters.azureml_cli_version }}
- task: AzureCLI@2
displayName: Run training
inputs:
azureSubscription: $(SERVICE_CONNECTION)
scriptType: bash
scriptLocation: inlineScript
inlineScript: |
az ml job create -f $(scriptRoot)/azure-ml-job.yaml \
--set inputs.epochs=${{ parameters.epochs }} \
--resource-group $(RESOURCE_GROUP) --workspace-name $(WORKSPACE)Даже для тех, кто не знаком с синтаксисом, надеемся, что ясно, что основная команда, которая выполняется, отличается только незначительно от той, которая определена в нашем Makefile!
Что насчет развертывания?
В этой статье мы в основном сосредоточились на сценариях обучения и уделили мало внимания задачам развертывания. Хотя многие подходы MLOps поощряют разделение рабочих процессов обучения и развертывания, мы предпочитаем подойти к этому вопросу по-другому. Рассмотрим следующее:
- Для развертывания модели часто требуется некоторый конкретный код, связанный с нашей моделью. Например, это может быть обработчик, который определяет, как обрабатывать входящие запросы перед передачей их модели.
- В большинстве случаев мы должны иметь возможность запускать развертывание локально, даже если это только для тестирования или разработки.
- Некоторые артефакты развертывания, вероятно, будут определены на уровне спецификации. Например, в AzureML, аналогично определению обучающих запусков, мы можем использовать файлы YAML для определения информации, такой как используемые вычислительные устройства, имена наших конечных точек и способы маршрутизации трафика между различными версиями развертывания (например, Azure ML docs для развертывания).
Имея в виду вышесказанное, мы считаем, что это следует совместить с кодом, специфичным для науки о данных и связанным с нашей задачей, и рассматривать это как часть той же логической компоненты! Поскольку нет зависимостей вверх, не имеет значения для спецификации задачи или триггера оркестрации, является ли это тренировочным или развертывающим выполнением. Кроме того, обработка вопросов обучения и развертывания как одной логической компоненты предоставляет нам много гибкости для объединения задач обучения и развертывания в один конвейер, если это необходимо! Например:
root
├── config.env
├── data
├── docs
├── notebooks
├── orchestration
├── Makefile
└── src
├── common
└── digit_recognition
└── deploy
│ ├── Dockerfile
│ ├── handler.py
│ └── torchserve-deployment.yaml
└── environment
│ └── Dockerfile
├── azure-ml-job.yaml
└── train.pyПоскольку последовательность шагов, необходимых для развертывания модели, обычно очень специфична в зависимости от используемых технологий, мы опускаем пример здесь, так как считаем, что это в значительной степени повторяло бы концепции, которые мы уже рассмотрели. Однако шаги, необходимые для расширения нашего шаблона для включения функционала развертывания модели PyTorch в Azure ML с использованием TorchServe, приведены в репозитории AzureML Scaffolding Extensions.
Заключение
Мы надеемся, что мы предоставили ясное введение в то, как мы думаем о структуре проектов по машинному обучению, а также о преимуществах нашего подхода.
Хотя мы строили все с нуля с целью постепенно формировать интуицию в течение этой статьи, мы обычно используем шаблон AzureML Scaffolding как надежную, но гибкую отправную точку при начале новых проектов; пожалуйста, попробуйте! Кроме того, мы также предлагаем репозиторий AzureML Scaffolding Extensions как базу для использования поверх базового шаблона.
Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.