В ходе работы над одним большим проектом (большим по замыслу), случайно родился другой проект. Дакота парсер — дочерний проект отнял больше времени, чем рассчитывал изначально. Расскажу о технических вопросах, на которых зависал какое-то продолжительное время и что из всего этого получилось.
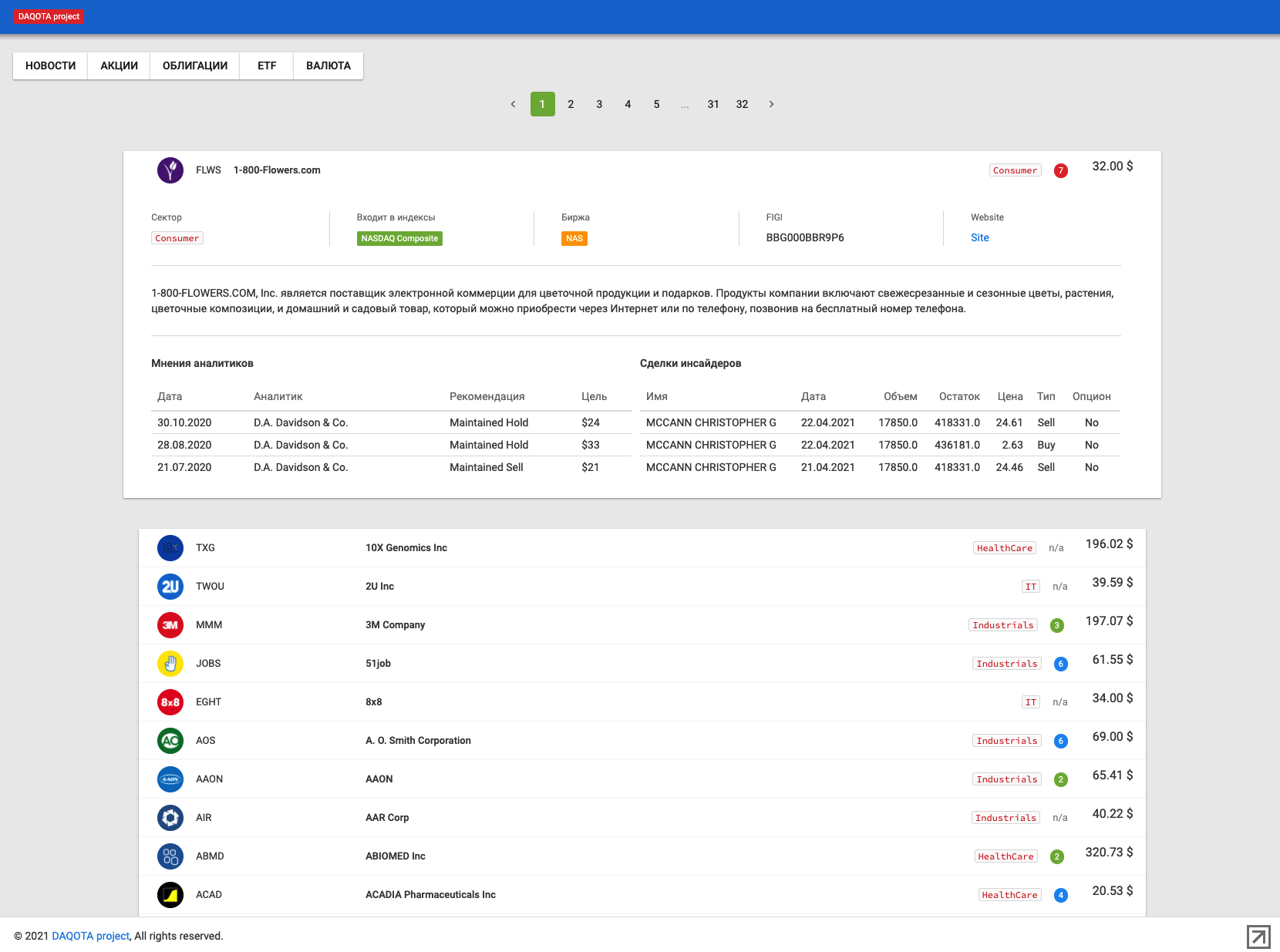
DAQOTA project — собирает информацию из более чем 150 источников, получается более 10 тыс заметок ежедневно.
Для удобства контроля за работой парсера, часть собранной информации выводится на сайте, но много так и остается скрыто в базе данных.
О чем статья?
- Общее описание DAQOUTA project (Дакота парсер)
- Какая платформа использовалась
- Использование и настройка Scrapy
- Собираем информацию путем реинжиниринга внутреннего api сайта
- Сбор информации из XML/RSS-фида
- Сбор информации с сайта с обогащением информации
Че делается в целом?
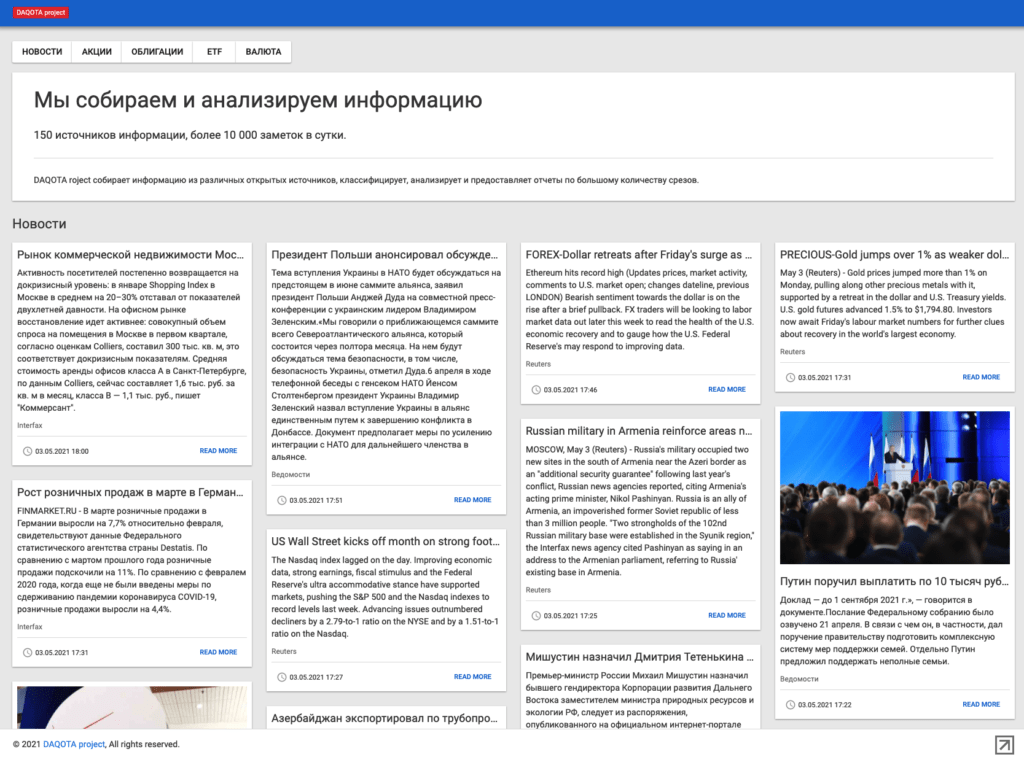
Для сбора информации используются следующие источники:
- новостные сайты
- брокерские и биржевые api
- сайты с отзывами
- новостные телеграмм-каналы
- сайты с статьями/инструкциями/описаниями
- сайты и телеграмм-каналы с биржевыми сигналами/прогнозами/стратегиями
- информация о сделках инсайдеров
Есть возможность отдавать собранную информацию по api, всю, или по определенным критериям, as is или предварительно обработанную или обогащенную другой информацией.

Сбор информации изначально задумывался, как вспомогательный модуль для биржевого стратега-анализатора (это и есть большой проект). Но, со временем Дакота, похоже, превращается в отельный самостоятельный проект. Хотя, сейчас я не до конца понимаю, как его развивать в отдельности.
Далее будет много технических подробностей и описание «как это все программировалось».
Технические параметры проекта Дакота парсер
Хостинг для проекта vscale.io ubuntu 20.04 1gb 30gb / 400 руб. /мес. — хороший дешевый вариант для старта. Сейчас такой конфигурации уже не хватает — скачивается большо объем инфы, нужен побольше входящий канал; нужно больше оперативной памяти для работы с базой и одновременно, чтобы держать множество потоков парсера.
База MongoDb — для парсинга лучше использовать noSql базу, так как мы получаем разнородную информацию, которую на этапе парсинга удобнее сохранять как есть. И если потом понадобится, можно отдельно структурировать и пересохранять в sql-базу. Хотя мне это и не требуется. Веб-сервер — nginx.
Фреймворк для парсера scrapy (python).
Сайт dq9.ru с использованием flask и шаблон дизайна Altair — Admin Material Design UIkit Template.
Часть проекта (которая касается данной статьи) я выложил в отдельном репозитории.
Дакота парсер рабоатет на scrapy
Scrapy это python-фреймворк для сбора данных из интернета. Подробное описание можно найти в интернете, здесь я приведу несколько тонкостей по работе с scrapy. Текст ниже удобнее читать, если уже что-то прочитали про scrapy.
Scrapy делает запросы по заданным адресам и дает нам для работы ответы в виде dom-объекта. Чтобы разбирать страницу, как правило используем xpath (отличный cheat-sheet).
В разборе содержимого страницы сильно помогает плагин CrhoPath для хрома или FF. На мой взгляд, в FF удобнее заниматься разбором страницы. К тому же xml и json фиды FF сразу отрисовывает в дерево, а в Chrome такого по умолчанию нет.
Начало работы с scrapy
1. Установка и инициализация
Устанавливаем библиотеку pip install Scrapy, стартуем новый проект scrapy startproject project_name, создаем первого паука scrapy genspider name domain.ru. После этих действий у нас сгенерируется много новых файлов, однако нет точки запуска (в туториале описан не совсем удобный способ запуска). Сделаем отдельный файл инициализации и запуска, например main.py. Так еще будет проще дебажить.

2. Настройки — Settings.py
В файле settings.py добавим переменные LOG_ENABLED и LOG_LEVEL (их нет по умолчанию). Установим COOKIES_ENABLED = True, ROBOTSTXT_OBEY = False. Обязательно заполните человеческое USER_AGENT, значение можно взять вбив в хром строчку chrome://version/
Раскоментируйте ITEM_PIPELINES
3. Ловим завершение работы
Scrapy является многопоточной системой, поэтому не так просто понять, когда паук закончит работу. Для того, чтобы поймать завершение программы, используется диспетчер и сигналы from scrapy import signals
from pydispatch import dispatcher
В инициализации класса паука пишем dispatcher.connect(self.spider_closed, signals.spider_closed),
где первый параметр — метод, который вызывается при закрытии паука (второй параметр). Какие есть сигналы, смотрим в документации.
Собираем информацию путем реинжиниринга внутреннего api сайта
Расскажу на примере получения экономических новостей с сайта Тинькофф-инвестиции.
Если попробуем стартовать с этой страницы, то в ответ получим пустую ленту, новостей на странице не будет.

А новости загружаются уже после того, как загрузилась html-страница. Логично предположить, что догрузка идет через json. Открываем developers tools в браузере, идем Network — XHR, обновляем страницу, и начинаем исследовать появившиеся запросы. Находим запрос вида https://www.tinkoff.ru/api/invest/smartfeed-public/v1/feed/api/main?sessionId=HkvtZnQuGezPspCmEUpx3GIQ06DjCxLx.m1-prod-api12 в ответе видим, 30 новостей (у меня 30, но может быть и друго е количество).
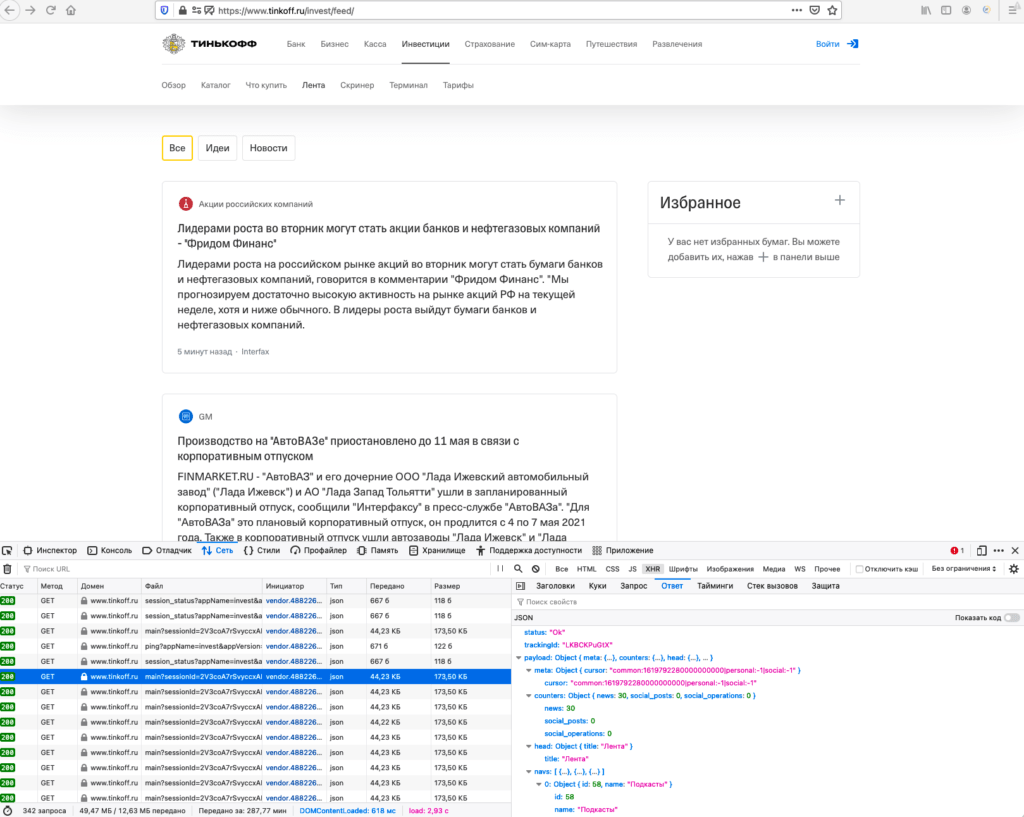
Ответ мы получаем в виде структуры данных, для удобства работы с ней преобразуем к json-структуре j_body = response.json()
Откуда взять sessionId для конструирования запроса? А вот, например, можно отсюда https://www.tinkoff.ru/api/common/v1/session?origin=web%2Cib5%2Cplatform (тоже найдено при разборе запросов страницы) — в ответ приходит: payload: "wzPRqHoITl5G2kPyNZeXOtuMWo2XWmxL.ds-prod-api02". То есть, вначале запрашиваем эту страницу, получаем сессию, потом запрашиваем страницу с api фида новостей.
Как получить следующую пачку новостей? Листаем страницу браузера вниз, и видим, что в ленту автоматом догружаются еще новости по аналогичному запросу. Только к запросу прибавляется значение cursor, а оно было у нас в предыдущем ответе. Все, гоняем в цикле запрос с курсором пока не надоест.
А как определить, что нам надоело? В ответе у каждой новости есть id, на него и будем ориентироваться. Я сделал так: при заходе на сайт, запрашиваю одну страницу новостей. Из ответа со списком новостей определяю максимальный номер id, запоминаю его в базу. При следующем заходе сравниваю запомненное значение с полученными данными. Если старое значение больше или равно числу в ответе, то прекращаю запрашивать новости.
Вот еще одна интересная штука с новостями
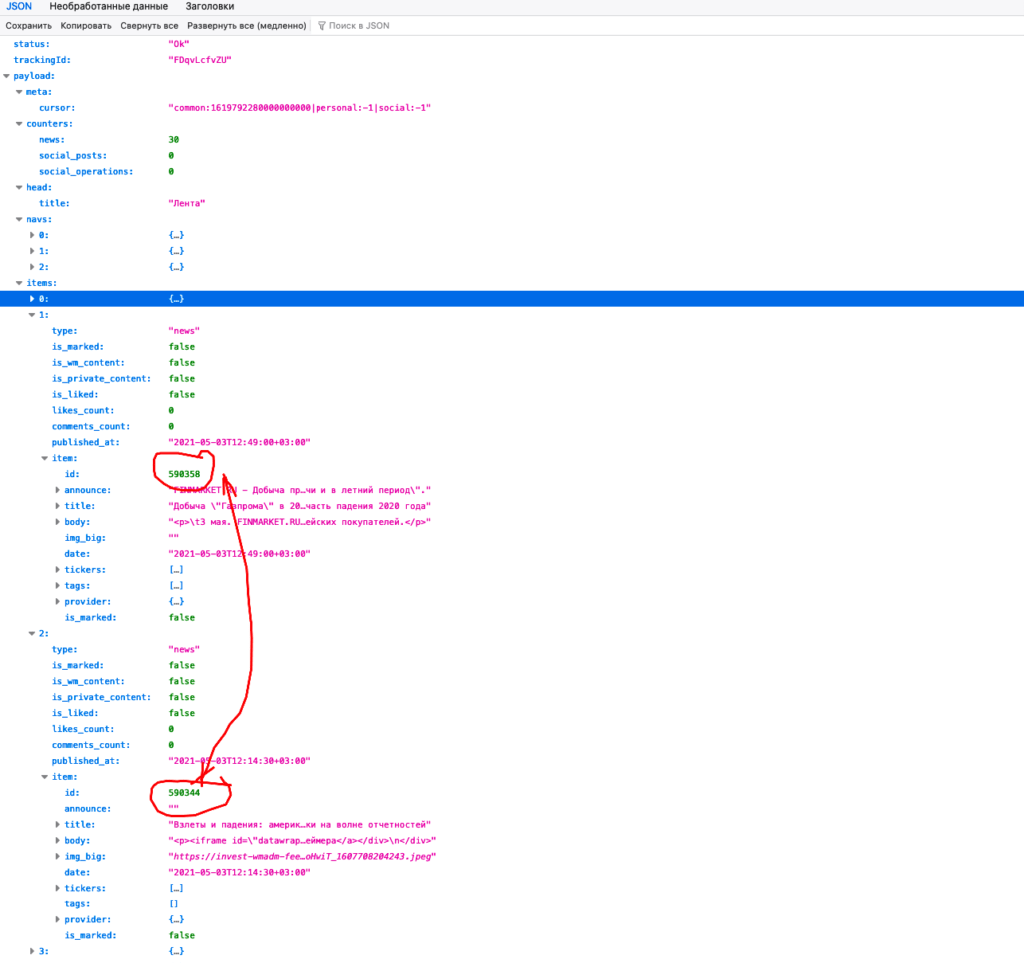
Если посмотреть на id новостей из ответа, то можно заметить, что цифры не по порядку, а с пропусками. А давайте потыкаем в пропущенные id? — ага, новости есть, но они скрыты из общей ленты. Вероятно, это черновые новости, которые редактор отсеял или, новости, которые отображаются в отдельных разделах, а не в общей ленте. Чтобы не собирать инфу с страницы (да и не получится так сразу, потому что и на отдельную страницу инфа запрашивается через json), найдем соответствующий запрос. Вот по этому урлу запрашивается отдельная новость https://www.tinkoff.ru/api/invest/smartfeed-public/v1/feed/api/news и в конце дописать id нужной новости. Не забываем дописать sessionId. В ответ получаем почти аналогичный ответ, как и в ленте. Отличие лишь в том, что нет группирующего узла items.
В общем, это почти все с парсингом ленты новостей
«Почти», потому что, надо еще поработать с исключениями, так как ответы не всегда приходят одинаковые. Например, есть тип новости «company_news», в котором лежит не одна новость, а может быть несколько сгруппированных вместе.
Формируем item после получения/выделения отдельной новости и отправляем через yield в piplines для сохранения в базу.
Еще один момент! Сделайте в классе item пустое поле _id, тогда при сохранении в mongodb там корректно и без ошибок подставится id документа из базы.
Сбор информации из XML/RSS-фида
На примере сбора новостей с сайта vtimes.io
Если посмотреть html-код страницы сайта, то внутри head можно найти ссылочку на https://www.vtimes.io/rss. Открываем и смотрим, что там такое. Все отлично, и картинка, и полный текст статьи, и все остальное!
Для работы с xml, у скрапи есть есть класс XMLFeedSpider, от него наследуем нашего паука. В отличии от предыдущего случая, паук будет стартовать с метода parse_node (а в тинькове мы стартовали с метода parse).

При разборе фида было несколько нюансов
Для начала работы, необходимо добавить две специальные переменные: iterator = 'iternodes'
itertag = 'item'
первая говорит, что итератор типа ноды, вторая — что в цикле перебираем узлы, которые в xml-фиде названы item
Чтобы достать содержимое , нужно предварительно установить правило namespace, из заголовка фида, автоматом у меня почему-то не подгрузились. Первой строчкой метода напишем: node.register_namespace('content', 'http://purl.org/rss/1.0/modules/content/'), тогда текст статьи можно получить с помощьюbody = node.xpath('//content:encoded/text()')
В текст статьи авторы запихнули еще блок с related, его я решил вырезать: body = html.unescape(re.sub(r"<aside.", '', body, flags=re.DOTALL))
главное не забыть дописать флаг, иначе регулярка не будет работать, так как в тексте есть переводы строки и табуляции.
Чтобы понять, что уже сохраняли, а что нет, так же как и в предыдущем случае, будем ориентироваться на id статьи. В этот раз id статьи берем из хвостика урла статьи (поле link): int(re.search('.-a(\d*)$', link).group(1))
Статьи появляются не слишком часто, как в новостных лентах, даже если заходить на сайт раз в сутки, то одного запроса фида будет достаточно.
Сбор информации с сайта с обогащением информации
На примере ru.investing.com
Что означает сбор информации с обогащением? Допустим мы получаем текст статьи/новости, а по тексту есть ссылки на еще какие-то материалы. Мы хотим сохранить нашу статью и еще в этот item дописать информацию со страниц по ссылкам. В данном случае у нас есть текст новости и ссылки на тикеры компаний, про которые говориться в тексте. При этом при наведении курсора на тикер, появляется попап с информацией по тикеру на момент написания текста.
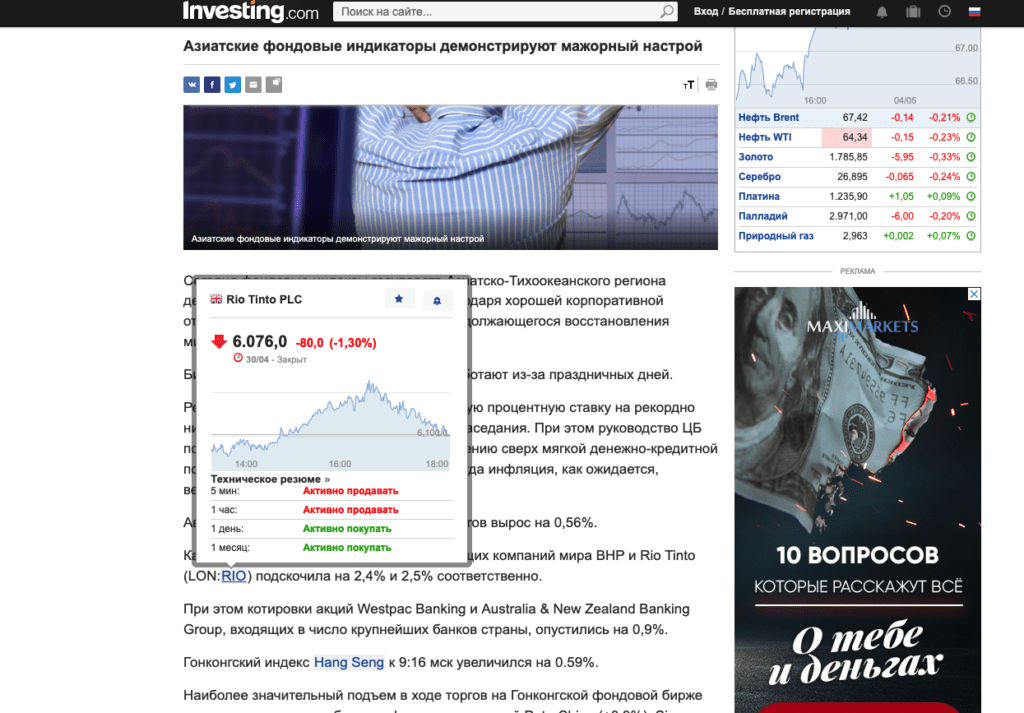
Проблема заключается в том, что парсер идет сохранять item в тот момент, когда доходит до конца ветки обхода, а нам надо, чтобы сохранение шло на предпоследнем шаге, при условии, что все дочерние страницы закончились. Что еще усложняется многопотоковостью и асинхронностью.
Логика решения этого вопроса такая:
Формируем список страниц/ссылок, которые надо дополнительно обойти.
При переходе к парсингу дочерней страницы тащим с собой item и список страниц для обхода.
При каждом заходе в парсинг дочерней страницы, выталкиваем из списка очередной урл, добавляем полученные с дочерней страницы данные в item.
Если список оказался пуст, то возвращаем только item (в котором уже будет сохранена дополнительная инфа со всех дочерних страниц), если обошли еще не все страницы, то вернем объект request.
В точке, куда вернемся (это предпоследний шаг, то есть шаг где мы парсили страницу со статьей), мы смотрим, что нам вернулось: если item, значит все собрали, делаем yield item и уходим сохранять в piplines.
Если не item вернулся, то идем на следующую итерацию сбора инфы с дочерней страницы (при этом тащим с собой item и список оставшихся страниц).
Несколько нюансов Дакота парсер
Дочерние страницы собираются не через response.follow, а через Request у меня это выгладит такrequest = Request(t.pop(), self.parse_hidden_ticker, meta={'item': item, 't': t}, dont_filter=True)
где t это список ссылок, которые надо еще обойти. В этом случае параметры между шагами мы таскаем не через cb_kwargs={}, а через meta={}
Если scrapy натыкается на ссылку, которую он уже обходил в этом сеансе, то по умолчанию второй раз он по ней не пойдет. В нашем случае это проявляется, если в разных статьях попадаются ссылки на одну и ту же компанию (хотя может и в разное время). Например, несколько статей и все пишут про APPL. Чтобы парсер заходил на Apple из каждой страницы, поставим в запросе флаг dont_filter=True
Информация по акции (попап), получается с помощью json-запроса, находим так же как и в кейса с тиньковым. Запрос к тикеру идет вот сюда: https://sbcharts.investing.com/charts_xml/jschart_sideblock_{}_area.json
в фигурных скобках подставляем id тикера.
В следующей части статьи про Дакота парсер:
- Сбор инфы по api, Сбор новостей из телеграмм-каналов
- Как потом вся информация собирается вместе в базе
- И как все это отображается на сайте dq9.ru
Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.