
Новые и малоизвестные возможности Pandas, о которых полезно знать каждому специалисту по Data Science. Сколько раз вы говорили: «было бы здорово, если бы я мог это сделать в Pandas»? Возможно, вы это и можете! Pandas настолько огромна и глубока, что она позволяет выполнять практически любые операции с таблицами, которые вы можете себе представить. 25 полезных возможностей Pandas сократят ваш код и сделают его более читабельным. Так как многие элегантные возможности, решающие редко возникающие задачи и уникальные сценарии, теряются в глубинах документации, затертые более часто используемыми функциями.
Эта статья попытается заново открыть для вас многие возможности Pandas и показать, что она может намного больше, чем вам казалось.
1. ExcelWriter
ExcelWriter – это обобщенный класс для создания файлов Excel (с листами!) и записи в них DataFrame. Допустим, у нас есть два набора данных:
# Загрузим два набора данных
diamonds = sns.load_dataset("diamonds")
tips = sns.load_dataset("tips")
# Пишем оба в один и тот же файл Excel
with pd.ExcelWriter("data/data.xlsx") as writer:
diamonds.to_excel(writer, sheet_name="diamonds")
tips.to_excel(writer, sheet_name="tips")У класса есть дополнительные атрибуты для определения используемого формата DateTime: хотите ли вы создать новый файл Excel или изменить существующий, что делать, если лист существует и т. п. Детали см. в документации.
2. pipe
pipe – одна из лучших функций для проведения очистки данных в Pandas кратким и четким образом. Она позволяет объединять несколько пользовательских функций в одну операцию.
Для примера допустим, что у вас есть функции удаления дубликатов (remove_duplicates), удаления выбросов (remove_outliers) и кодирования категориальных признаков (encode_categoricals), каждая со своими аргументами. Вот как вы можете применить все эти функции одной операцией:
df_preped = (diamonds.pipe(drop_duplicates).
pipe(remove_outliers, ['price', 'carat', 'depth']).
pipe(encode_categoricals, ['cut', 'color', 'clarity'])
)Мне нравится, что эта функция похожа на конвейеры Sklearn. Вы можете сделать с ее помощью намного больше – читайте документацию или эту полезную статью.
3. factorize
Эта функция – альтернатива LabelEncoder из Sklearn в Pandas:
# Обратите внимание на [0] в конце
diamonds["cut_enc"] = pd.factorize(diamonds["cut"])[0]
>>> diamonds["cut_enc"].sample(5)
52103 2
39813 0
31843 0
10675 0
6634 0
Name: cut_enc, dtype: int64В отличие от LabelEncoder‘а, factorize возвращает кортеж из двух значений: закодированный столбец и список уникальных категорий.
codes, unique = pd.factorize(diamonds["cut"], sort=True)
>>> codes[:10]
array([0, 1, 3, 1, 3, 2, 2, 2, 4, 2], dtype=int64)
>>> unique
['Ideal', 'Premium', 'Very Good', 'Good', 'Fair']4. explode – Бабах!
explode – это функция с интересным именем (взрыв). Давайте сначала посмотрим пример, а потом объясним:
data = pd.Series([1, 6, 7, [46, 56, 49], 45, [15, 10, 12]]).to_frame("dirty")
>>> data
В столбце dirty есть две строки, в которых хранятся не единственные значения, а списки. Такие данные часто встречаются в опросах, поскольку некоторые вопросы допускают несколько ответов.
>>> data.explode("dirty", ignore_index=True)
explode распространяет данные из ячейки с массивоподобным значением на несколько строк. Установите ignore_index в True, чтобы сохранить числовой индекс по порядку.
5. squeeze
Еще одна функция с забавным именем – это squeeze (сжатие), используемая в очень редких, но надоедливых случаях. Один из таких случаев – когда запрос подмножества из DataFrame возвращает единственное значение. Рассмотрим следующий пример:
subset = diamonds.loc[diamonds.index < 1, ["price"]]
>>> subset
Хотя результат – всего одна ячейка, он возвращается как DataFrame. Это неудобно, поскольку вам придется еще раз использовать .loc и передать как имя столбца, так и индекс, чтобы получить цену.
Но если вы знаете про squeeze, нам не придется этого делать. Эта функция позволяет убрать оси из DataFrame или Series, содержащих единственную ячейку. Например:
>>> subset.squeeze()
326Теперь мы получили скалярное значение. Можно также указать, какую ось нужно убрать:
>>> subset.squeeze("columns") # или "rows"
0 326
Name: price, dtype: int64Обратите внимание, что squeeze работает только с DataFrame и Series, имеющими единственное значение.
6. between
Это довольно изящная функция для бинарного индексирования числовых признаков по принадлежности диапазону:
# Выбрать бриллианты с ценой от 3500 до 3700 долларов
diamonds[diamonds["price"]\
.between(3500, 3700, inclusive="neither")].sample(5)
7. T
У всех DataFrame есть простой атрибут T, что значит «транспонирование». Возможно, вы не будете часто его использовать, но я считаю его довольно полезным при выводе DataFrame’ов после метода describe():
>>> boston.describe().T.head(10)
Набор данных о недвижимости Бостона содержит 30 числовых столбцов. Если просто вызвать describe, результирующий DataFrame будет сжат по горизонтали, и сравнить статистику будет трудно. Транспонирование поменяет оси местами, и по горизонтали будут уже статистические параметры.
8. Стилизатор Pandas
А вы знали, что Pandas позволяет вам задавать стили DataFrame’ов?
У них есть атрибут style, открывающий дверь к настройкам и стилям, ограниченным только вашими знаниями HTML и CSS. Я не буду рассказывать обо всем, что вы можете сделать с помощью style, покажу лишь свои любимые функции:
>>> diabetes.describe().T.drop("count", axis=1)\
.style.highlight_max(color="darkred")
Мы выделили ячейки, содержащие максимальные значения каждого столбца. Еще один полезный стилизатор – background_gradient, присваивающий ячейкам градиентный фоновый цвет на основе их значений:
diabetes.describe().T.drop("count", axis=1).style.background_gradient(
subset=["mean", "50%"], cmap="Reds"
)
Это особенно полезно, если вы вызываете describe для таблицы со множеством столбцов и хотите сравнить суммарную статистику. Подробности см. в документации по стилизатору.
9. Опции Pandas
Как и в Matplotlib, в Pandas есть глобальные настройки, которые можно изменять для настройки поведения по умолчанию:
>>> dir(pd.options)
['compute', 'display', 'io', 'mode', 'plotting']Эти настройки разделены на 5 модулей. Давайте посмотрим, какие настройки есть в модуле display:
>>> dir(pd.options.display)
['chop_threshold',
'max_columns',
'max_colwidth',
'max_info_columns',
'max_info_rows',
'max_rows',
...
'precision',
'show_dimensions',
'unicode',
'width']В группе display много настроек, но я в основном использую max_columns и precision:
# Убрать лимит на изображаемое количество столбцов
pd.options.display.max_columns = None
# Показывать только 5 цйфр после запятой
pd.options.display.precision = 5 # избавиться от научной нотацииБольше подробностей об этих замечательных настройках можно найти в документации.
10. convert_dtypes
Все мы знаем, что Pandas имеет раздражающую привычку присваивать столбцам тип данных object. Вместо того чтобы назначать типы данных вручную, вы можете использовать метод convert_dtypes, который пытается подобрать наиболее подходящий тип данных:
sample = pd.read_csv(
"data/station_day.csv",
usecols=["StationId", "CO", "O3", "AQI_Bucket"],
)
>>> sample.dtypes
StationId object
CO float64
O3 float64
AQI_Bucket object
dtype: object
>>> sample.convert_dtypes().dtypes
StationId string
CO float64
O3 float64
AQI_Bucket string
dtype: objectК сожалению, метод не может разбирать даты из-за нюансов различных форматов их представления.
11. select_dtypes
Функция, которую я использую постоянно – это select_dtypes. Ее функционал очевиден из ее названия: выбор по типам данных. У нее есть параметры include и exclude, позволяющие выбрать столбцы, включая или исключая определенные типы данных. Например, можно выбрать только числовые столбцы, указав np.number:
# Выбрать только числовые столбцы
diamonds.select_dtypes(include=np.number).head()
или, наоборот, исключить их:
# Исключить числовые столбцы
diamonds.select_dtypes(exclude=np.number).head()

12. mask
Функция mask позволяет быстро заменять значения в тех ячейках, для которых выполняется определенное условие. Предположим, что у нас есть данные опроса людей от 50 до 60:
# Create sample data
ages = pd.Series([55, 52, 50, 66, 57, 59, 49, 60]).to_frame("ages")
ages
Мы будем считать возраст, выходящий за границы от 50 до 60 лет, ошибками ввода (таких ошибок две – 49 и 66 лет), которые заменим на NaN:
ages.mask(cond=~ages["ages"].between(50, 60), other=np.nan)
Таким образом, mask заменяет значения ячеек, не удовлетворяющие cond, значениями other.
13. min и max по строкам и столбцам
Хотя функции min и max широко известны, они имеют еще одно применение, полезное для особых случаев. Давайте рассмотрим следующий набор данных:
index = ["Diamonds", "Titanic", "Iris", "Heart Disease", "Loan Default"]
libraries = ["XGBoost", "CatBoost", "LightGBM", "Sklearn GB"]
df = pd.DataFrame(
{lib: np.random.uniform(90, 100, 5) for lib in libraries}, index=index
)
>>> df
Этот DataFrame содержит воображаемую точность моделей, полученных в результате четырех видов градиентного бустинга на пяти различных наборах данных. Мы хотим найти лучшую точность на каждом наборе. Вот как элегантно это можно сделать с помощью max:
>>> df.max(axis=1)
Diamonds 99.52684
Titanic 99.63650
Iris 99.10989
Heart Disease 99.31627
Loan Default 97.96728
dtype: float64Если вы хотите найти максимум или минимум по каждому столбцу, достаточно изменить 1 на 0.
14. nlargest и nsmallest
Иногда вам недостаточно получить максимальное или минимальное значение столбца. Вы хотите получить N максимальных (или минимальных) значений. Для этого пригодятся функции nlargest и nsmallest. Давайте выведем 5 самых дорогих и самых дешевых бриллиантов:
diamonds.nlargest(5, "price")
diamonds.nsmallest(5, "price")
15. idxmax и idxmin
Когда вы вызываете max или min для столбца, pandas возвращает максимальное или минимальное значение. Однако иногда вам нужна позиция этого значения, а не оно само. Для этого используйте функции idxmax и idxmin:
>>> diamonds.price.idxmax()
27749
>>> diamonds.carat.idxmin()
14Можно также задать axis=’columns’, при этом функции будут возвращать номер индекса нужного столбца.
16. value_counts с параметром dropna=False
Для нахождения процента пропущенных значений чаще всего используется комбинация isnull и sum и деление на длину массива. Но вы можете сделать то же самое с помощью value_counts, если задать соответствующие аргументы:
ames_housing = pd.read_csv("data/train.csv")
>>> ames_housing["FireplaceQu"].value_counts(dropna=False, normalize=True)
NaN 0.47260
Gd 0.26027
TA 0.21438
Fa 0.02260
Ex 0.01644
Po 0.01370
Name: FireplaceQu, dtype: float64В этом столбце 47% пустых значений (NaN).
17. clip
Обнаружение и удаление выбросов часто используется в анализе данных. Функция clip позволяет очень легко найти выбросы, выходящие за пределы диапазона и заменить их предельными значениями. Давайте вернемся к примеру с возрастами людей от 50 до 60:

На этот раз мы заменим значения, выходящие за диапазон от 50 до 60, крайними значениями диапазона.
ages.clip(50, 60)
Быстро и эффективно!
18. at_time и between_time
Эти функции могут пригодиться при работе с данными, разделенными по времени с высокой степенью детализации. Давайте создадим таблицу, содержащую 100 часовых интервалов:
index = pd.date_range("2021-08-01", periods=100, freq="H")
data = pd.DataFrame({"col": list(range(100))}, index=index)
>>> data.head()
Функция at_time позволяет выбирать значения по заданным дате или времени. Давайте выделим все строки, соответствующие 15.00:
data.at_time("15:00")
Здорово, правда? А теперь давайте используем between_time, чтобы выделить строки в заданном интервале времени:
from datetime import datetime
>>> data.between_time("09:45", "12:00")
Заметьте, что обе функции требуют DateTimeIndex, и они работают только с временем. Если вы хотите выделить строки в определенном интервале DateTime, используйте between.
19. bdate_range
bdate_range – это функция для быстрого создания индексов TimeSeries с частотой в один бизнес-день.
series = pd.bdate_range("2021-01-01", "2021-01-31") # A period of one month
>>> len(series)
21Частота в бизнес-день часто встречается в финансовом мире. Значит, эта функция может оказаться полезной для переиндексирования существующих временных интервалов функцией reindex.
20. autocorr
Один из важнейших компонентов анализа временных последовательностей – это изучение автокорреляции переменной. Автокорреляция – это старый добрый коэффициент корреляции, но взятый по сравнению с лагом той же последовательности. Точнее, автокорреляция при lag=k вычисляется следующим образом:
1. Последовательность сдвигается k периодов времени:
time_series = tips[["tip"]]
time_series["lag_1"] = time_series["tip"].shift(1)
time_series["lag_2"] = time_series["tip"].shift(2)
time_series["lag_3"] = time_series["tip"].shift(3)
time_series["lag_4"] = time_series["tip"].shift(4)
# time_series['lag_k'] = time_series['tip'].shift(k)
>>> time_series.head()
2. Рассчитывается корреляция между исходным значением и каждым лагом.
Вместо того чтобы делать все это вручную, вы можете использовать функцию Pandas autocorr:
# Автокорреляция tip при lag_8
>>> time_series["tip"].autocorr(lag=8)
0.07475238789967077О важности автокорреляции для анализа временных рядов можно прочитать в этой статье.
21. hasnans
Pandas предлагает метод для простой проверки, содержит ли Series какие-либо пустые значения – атрибут hasnans:
series = pd.Series([2, 4, 6, "sadf", np.nan])
>>> series.hasnans
TrueСогласно его документации, атрибут существенно ускоряет производительность. Заметьте, что он работает только для Series.
22. at и iat
Эти два метода доступа к значениям – гораздо более быстрые альтернативы loc и iloc, но с существенным недостатком: они позволяют получить или изменить только одно значение:
# [index, label]
>>> diamonds.at[234, "cut"]
'Ideal'
# [index, index]
>>> diamonds.iat[1564, 4]
61.2
# Заменить 16541-ю строку столбца price
>>> diamonds.at[16541, "price"] = 1000023. argsort
Эту функцию стоит использовать каждый раз, когда вы хотите выделить индексы, образующие отсортированный массив:
tips.reset_index(inplace=True, drop=True)
sort_idx = tips["total_bill"].argsort(kind="mergesort")
# Теперь выведем значения `tips` в порядке сортировки по total_bill
tips.iloc[sort_idx].head()
24. Метод доступа cat
Общеизвестно, что Pandas позволяет использовать встроенные функции Python на датах и строках с помощью методов доступа вроде dt или str. Кроме того, в Pandas есть специальный тип данных category для категориальных переменных, как показано ниже:
>>> diamonds.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
price int64
x float64
y float64
z float64
cut_enc int64
dtype: objectЕсли столбец имеет тип category, над ним можно выполнять несколько специальных функций с помощью метода доступа cat. Например, давайте рассмотрим различные виды огранки бриллиантов:
>>> diamonds["cut"].cat.categories
['Ideal', 'Premium', 'Very Good', 'Good', 'Fair']Есть и такие функции, как remove_categories, rename_categories и т. д.:
diamonds["new_cuts"] = diamonds["cut"].cat.rename_categories(list("ABCDE"))
>>> diamonds["new_cuts"].cat.categories
Index(['A', 'B', 'C', 'D', 'E'], dtype='object')Полный список функций, доступных через метод доступа cat, можно посмотреть здесь.
25. GroupBy.nth
Эта функция работает только для объектов GroupBy. После группировки она возвращает n-ю строку каждой группы:
diamonds.groupby("cut").nth(5)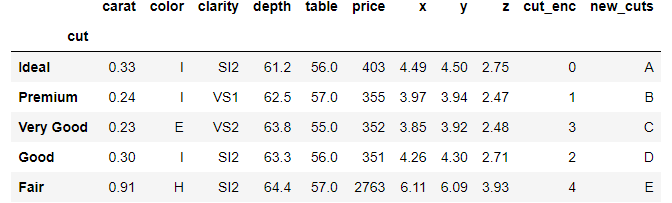
Заключение
Несмотря на то, что новые библиотеки вроде Dask и datatable потихоньку вытесняют Pandas благодаря их сверкающим новым возможностям для обработки огромных массивов данных, Pandas по-прежнему остается самым популярным средством манипуляции данными в экосистеме Data Science на Python.
Эта библиотека – образец для подражания, который другие пытаются имитировать и улучшить, поскольку она прекрасно интегрируется в современный стек SciPy.
Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.