
Ниже приведены 10 вопросов про микросервисную архитектуру, которые часто задают опытным разработчикам (мидлам и синьорам) со стажем от 5 до 10 лет. Возможно, вам так же будет интересная статья про продвинутые практики использования git.
1
Представьте, что вы работаете над микросервисом, который отвечает за обработку заказов. Однако из-за некоторых проблем сервис в настоящее время недоступен. Что бы вы сделали, чтобы гарантировать, что заказы не потеряются и смогут быть обработаны после восстановления сервиса?
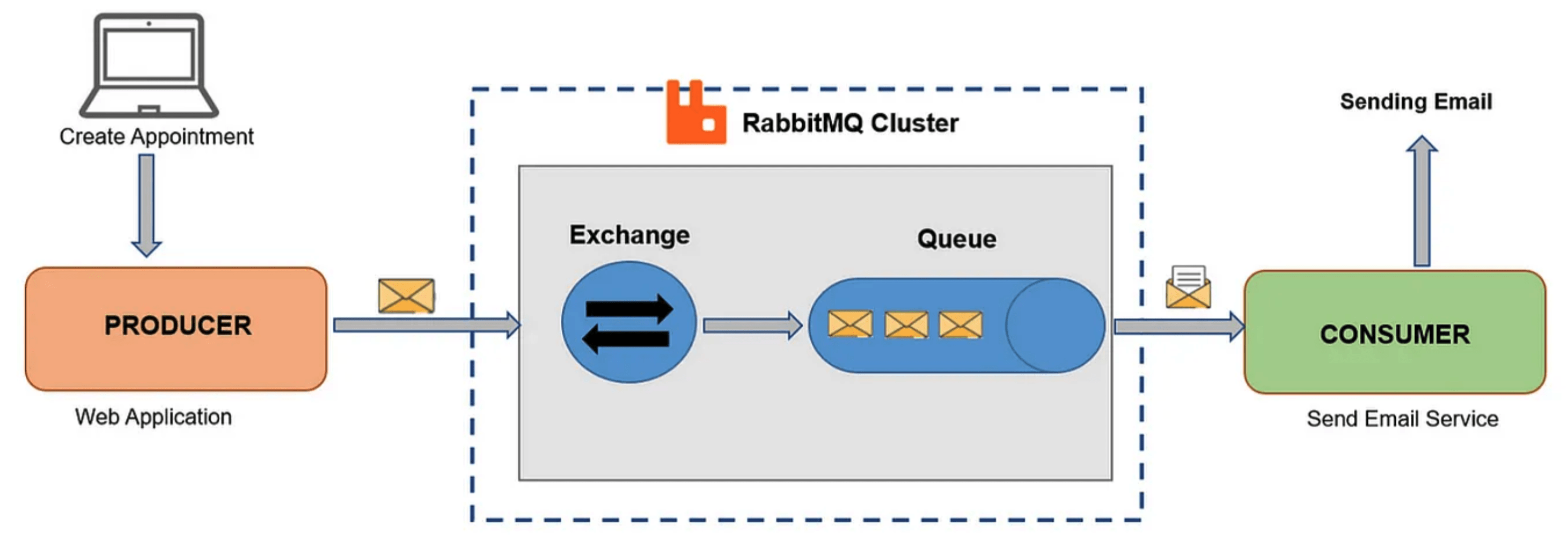
Ответ: Этот вопрос основан на том, как вы проектируете систему так, чтобы она не была сильно связана. Одно из возможных решений — это реализовать очередь сообщений между сервисом создания заказов и сервисом обработки заказов.
Заказы могут быть сохранены в очереди до тех пор, пока сервис обработки не станет доступен, после чего их можно будет забрать и обработать. В качестве очереди сообщений можно использовать RabbitMQ или Apache Kafka, оба позволяют создавать асинхронные микросервисы, которые не жестко зависят друг от друга.
Вот как может выглядеть микросервисная архитектура с использованием Apache Kafka:

2
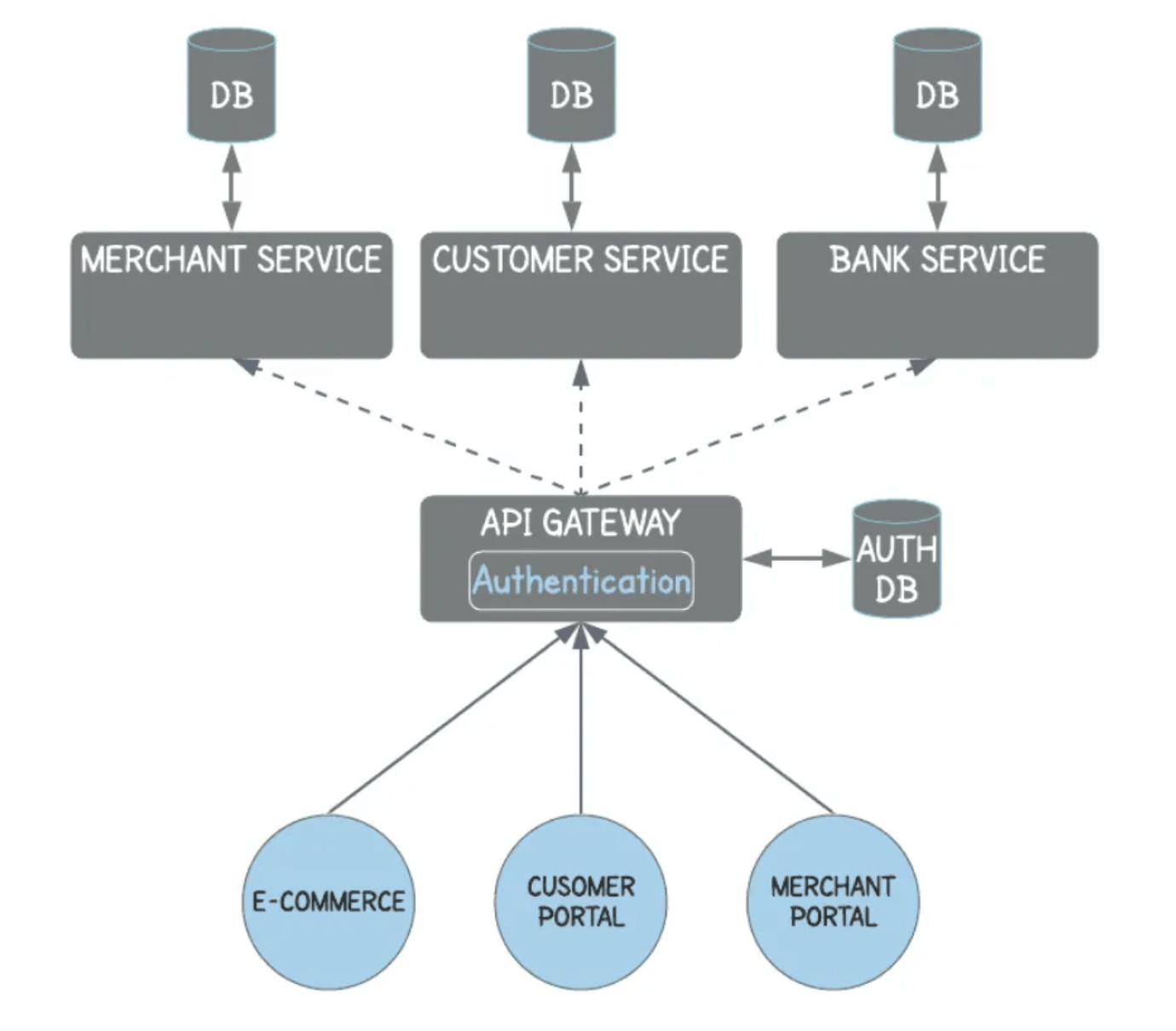
Предположим, у вас есть микросервис, отвечающий за аутентификацию пользователей. Как бы вы гарантировали, что сервис может обрабатывать большое количество запросов и обладает высокой доступностью?
Ответ: Этот вопрос проверяет вашу способность проектировать масштабируемую и надежную систему, которая может обрабатывать миллионы запросов. Одно из возможных решений — использование балансировки нагрузки и кластеризации.
Сервис может быть развернут на нескольких серверах, и балансировщик нагрузки распределит входящие запросы между ними.
Кроме того, сервис может быть спроектирован без состояния (stateless), что означает, что каждый запрос может быть обработан независимо без доступа к общему ресурсу.
Также можно использовать паттерн проектирования API Gateway для реализации аутентификации пользователей в архитектуре микросервисов.
3
Представьте, что вы работаете над микросервисом, который отвечает за генерацию отчетов. Как бы вы гарантировали, что отчеты генерируются правильно и эффективно, при этом минимизируя влияние на другие сервисы в системе?
Ответ: Этот вопрос также похож на предыдущий. Одно из возможных решений — использование кэширования и пакетной обработки. Сервис может кэшировать ранее сгенерированные отчеты и использовать их повторно, чтобы уменьшить необходимость генерации новых отчетов с нуля.
Кроме того, сервис может использовать пакетную обработку для генерации отчетов пакетами, а не по требованию, что дополнительно снизит нагрузку на систему.
4
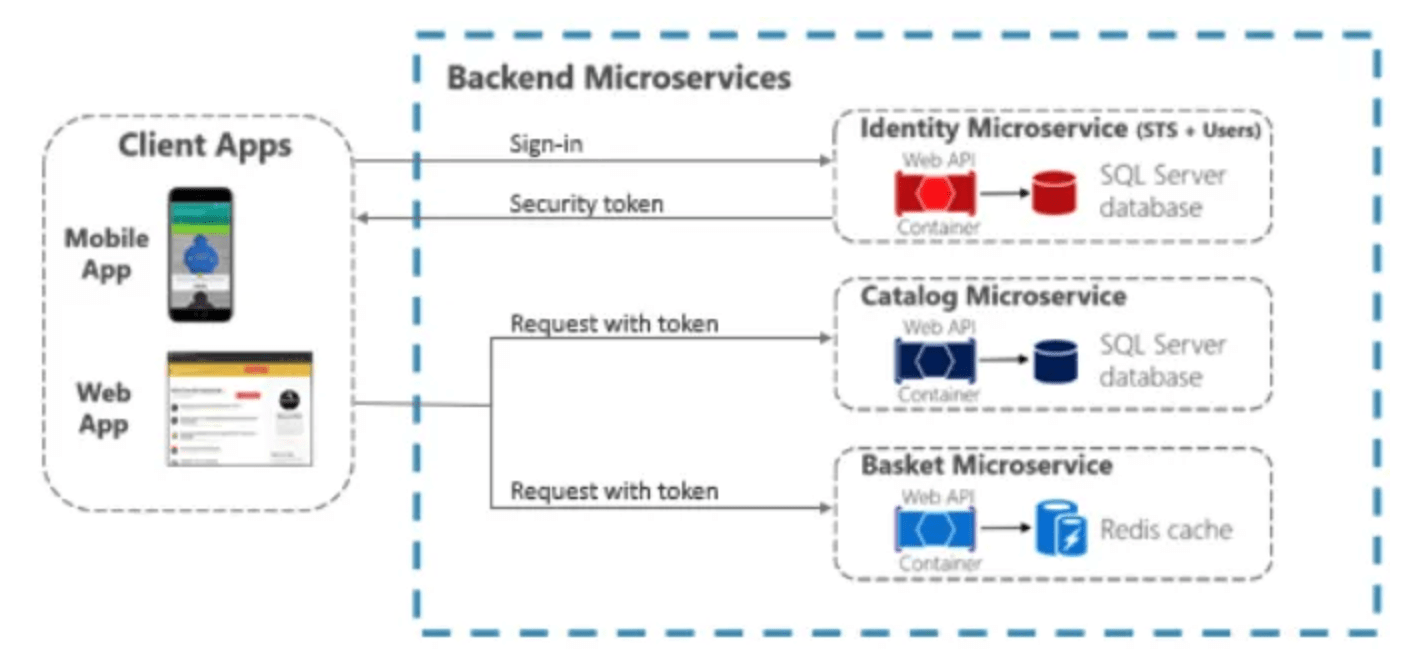
Предположим, у вас есть микросервис, отвечающий за обработку платежей. Как бы вы гарантировали, что сервис безопасен и что конфиденциальная информация о платежах защищена?
Ответ: Если вы проходили интервью на тему микросервисов, то, возможно, знаете, что обработка платежей — это любимая тема интервьюеров, так как это требует управления транзакциями, безопасности и невозможности потери данных.
Одно из возможных решений этой проблемы — это использование шифрования и токенизации. Информация о платежах может быть зашифрована перед передачей в сервис, что обеспечит ее защиту во время передачи.
Кроме того, сервис может использовать токенизацию для хранения информации о платежах в безопасной форме, заменяя конфиденциальные данные на незащищенные токены, которые можно безопасно хранить и передавать.
5
Представьте, что у вас есть микросервис, отвечающий за обработку отзывов пользователей. Как бы вы гарантировали быструю и точную обработку отзывов, минимизируя риск спама и злоупотреблений?
Ответ: Этот вопрос проверяет вашу способность защитить систему от злоупотреблений. Одно из возможных решений — это использование комбинации автоматической и ручной модерации.
Автоматическая модерация может использоваться для фильтрации очевидного спама и оскорбительного контента, тогда как более сложные случаи могут быть помечены для ручного рассмотрения.
Кроме того, сервис может реализовать ограничение количества запросов (rate limiting), чтобы предотвратить отправку большого количества отзывов в короткий промежуток времени.
6
Ваша команда разработала новый микросервис, который взаимодействует с несколькими другими сервисами. Однако вы замечаете, что производительность вашего микросервиса низкая. Каковы могут быть потенциальные причины этого и каким будет ваш подход для выявления и устранения проблемы?
Этот вопрос также популярен и в реальной практике, так как он касается выявления и устранения проблем с производительностью. Причинами низкой производительности могут быть следующие:
- Задержки в сети или плохое соединение между сервисами
- Узкие места в коде микросервиса или запросах к базе данных.
- Недостаточные ресурсы, выделенные для микросервиса или его зависимостей.
- Неэффективные протоколы связи или плохой дизайн сервиса.
Для выявления и устранения проблемы я бы использовал следующий подход:
- Провести тщательный анализ архитектуры микросервиса, включая зависимости и используемые протоколы связи.
- Использовать соответствующие инструменты мониторинга для выявления узких мест в коде, запросах к базе данных или связи между сервисами.
- Использовать распределенное трассирование для выявления задержек или проблем между сервисами.
- Проверить выделение ресурсов и, при необходимости, скорректировать их.
- Оптимизировать код и запросы при необходимости.
После выявления проблемы мы можем исправить ее, изменив архитектуру микросервиса, оптимизируя код и запросы, а также корректируя выделение ресурсов. Если необходимо, мы также можем пересмотреть протоколы связи или переосмыслить дизайн сервиса.
7
Представьте, что вы работаете в распределенной системе, где сообщение публикуется в очередь сообщений, и несколько сервисов его потребляют. Однако один из сервисов не смог обработать сообщение. Какой подход вы выберете для выявления причины проблемы и ее устранения?
Этот вопрос также довольно распространен на практике, но не отвечайте, что наша служба поддержки занимается этим или мы запускаем скрипт для исправления проблемы и т. д. Интервьюер интересуется вашим техническим решением.
Исходя из моего опыта, вы можете применить следующий подход для выявления причины проблемы и ее устранения:
- Проверьте журналы сервиса, который не смог обработать сообщение, чтобы увидеть, есть ли какие-либо сообщения об ошибках или исключениях.
- Проверьте конфигурацию сервиса, чтобы убедиться, что он правильно настроен для потребления сообщений из очереди.
- Проверьте соединение между сервисом и очередью сообщений, чтобы убедиться, что оно установлено и работает правильно.
- Проверьте очередь сообщений, чтобы узнать, было ли сообщение правильно опубликовано и доступно для потребления.
- Если проблема все еще не решена, проверьте, есть ли проблемы с сетью или брандмауэром, которые могут помешать сервису обработать сообщение.
Для устранения проблемы можно предпринять следующие шаги:
- Если проблема вызвана ошибкой в конфигурации или коде, ее можно исправить, обновив конфигурацию или код сервиса.
- Если проблема связана с сетью или брандмауэром, необходимо уведомить соответствующую команду для устранения проблемы.
- Если проблема связана с очередью сообщений, следует исследовать проблему с очередью и устранить любые проблемы.
- Если сообщение не может быть обработано, его можно переместить в специальную очередь для обработки ошибок и дополнительного анализа.
8
Представьте сценарий, в котором ваша команда разрабатывает новый микросервис, который требует данных (статических данных или данных о рынке) от другого сервиса. Однако у другого сервиса отличная от вашей структура данных, и вы не можете ее изменить. Каков будет ваш подход к решению этой ситуации?
Это также распространенная проблема на практике, с которой вы можете столкнуться при работе над проектом. Один из подходов к решению этой ситуации — использовать адаптер или слой трансформации между двумя сервисами. Этот адаптер может преобразовывать данные из формата, используемого исходным сервисом, в формат, ожидаемый целевым сервисом.
Другой подход — использовать платформу интеграции данных, такую как Apache Kafka или Apache Nifi, которая поможет преобразовывать данные на лету и делать их доступными для целевого сервиса.
Также можно создать копию данных в структуре данных целевого сервиса и синхронизировать ее с исходным сервисом регулярно с помощью инструмента для репликации данных, такого как Apache Flink или Apache Spark.
Важно обеспечить, чтобы выбранный подход не приводил к несогласованности данных или проблемам с качеством данных. Необходимо провести правильное тестирование и проверку, чтобы убедиться, что данные точно преобразуются и интегрируются между сервисами.
9
Представьте сценарий, в котором вы работаете в архитектуре микросервисов, где несколько сервисов зависят от общей базы данных. Однако вы обнаружили, что один из сервисов вызывает блокировку (deadlock) в базе данных. Какой будет ваш подход для решения этой ситуации и предотвращения повторения?
Если один из сервисов вызывает блокировку в общей базе данных, для решения этой ситуации и предотвращения повторения можно применить следующий подход:
- Выявить причину блокировки
Первым шагом будет выявление того, какой сервис вызывает блокировку и какие запросы вызывают проблему. Это можно сделать, проанализировав журналы базы данных и отслеживая активность в базе данных. - Исправить блокировку
После выявления причины блокировки следующим шагом будет ее устранение. Это можно сделать, изменив запросы, добавив индексы или оптимизировав схему базы данных. В некоторых случаях может потребоваться изменить код сервиса, вызывающего блокировку. - Внедрить механизмы блокировки и управления конкурентностью
Для предотвращения блокировок в будущем важно внедрить правильные механизмы блокировки и управления конкурентностью. Это можно сделать, используя механизмы блокировки на уровне базы данных, такие как блокировки на уровне строк, блокировки на уровне таблиц или блокировки на уровне базы данных. - Использовать распределенные транзакции
Еще один способ предотвратить блокировки — это использование распределенных транзакций. Это позволяет нескольким сервисам работать вместе в транзакционном режиме, обеспечивая согласованность данных между всеми сервисами. - Провести тестирование нагрузки
Наконец, важно провести тестирование нагрузки, чтобы убедиться, что система может справиться с большой нагрузкой и что база данных может обрабатывать параллельные запросы без вызова блокировок. Это поможет выявить возможные узкие места производительности и позволит предпринять проактивные меры.
Для того чтобы избежать подобных проблем, также рекомендуется, чтобы каждый сервис использовал свою собственную базу данных. Существует также шаблон, называемый «База данных на каждый микросервис», который стоит знать каждому разработчику.
10
Предположим, ваша команда разрабатывает новый микросервис, который взаимодействует с несколькими другими сервисами с помощью RESTful API. Однако эти API плохо задокументированы, и вы не имеете доступа к исходному коду других сервисов. Какой будет ваш подход для решения этой ситуации?
Ответ: Это также распространенный сценарий, с которым вы можете столкнуться при работе в реальном приложении. Чаще всего мне приходилось сталкиваться с тем, что нужно понять, какие REST API используют другие системы перед тем, как их использовать.
Один из возможных подходов для решения этой ситуации — использовать инструменты, такие как Swagger, для автоматической документации API. Swagger может проанализировать API и сгенерировать документацию, которой можно поделиться с другими разработчиками. Кроме того, инструменты, такие как Postman, могут использоваться для тестирования API и более полного понимания их функциональности.
Другой подход заключается в попытке связаться с владельцами других сервисов и запросить документацию по API или доступ к исходному коду. Если это невозможно, то можно провести обратную разработку API, проанализировав сетевой трафик и ответы на запросы.
Этот подход поможет понять функциональность API, но может быть менее надежным и масштабируемым.
В любом случае, важно подходить к таким ситуациям осторожно, так как недокументированные API могут быть подвержены неожиданному поведению или изменениям, что может повлиять на производительность и надежность архитектуры микросервисов.
11
Вы работаете в архитектуре микросервисов, где несколько сервисов обмениваются данными между собой с помощью синхронных RESTful API. Однако вы замечаете, что время ответа сервисов высокое, и система не масштабируется. Каков будет ваш подход для улучшения производительности и масштабируемости системы?
Существует несколько подходов, которые можно применить для улучшения производительности и масштабируемости архитектуры микросервисов, использующих синхронные RESTful API.
Вот некоторые возможные решения:
- Кэширование
Реализация кэширования может значительно улучшить время ответа и снизить нагрузку на систему. Хранение часто используемых данных или ответов в кэше позволяет избежать дорогостоящих запросов к сервисам и снижает время ответа. - Использование асинхронного обмена сообщениями
Асинхронный обмен сообщениями может улучшить масштабируемость и снизить время ответа, позволяя сервисам обмениваться данными без ожидания ответа. Разделение сервисов с помощью сообщений позволяет обрабатывать запросы параллельно и сокращает время ответа. - Внедрение балансировки нагрузки
Балансировка нагрузки позволяет распределить нагрузку между несколькими экземплярами сервиса и улучшить масштабируемость. С использованием балансировщиков нагрузки можно обеспечить равномерное распределение запросов и избежать перегрузки одного сервиса. - Оптимизация базы данных
Оптимизация базы данных, такая как индексирование, шардирование и разделение данных, может улучшить производительность и масштабируемость. Оптимизация базы данных позволяет снизить время ответа и улучшить масштабируемость системы. - Использование шлюзов API (API Gateways)
Шлюзы API могут предоставить центральную точку входа для сервисов и помочь с балансировкой нагрузки, кэшированием и ограничением скорости обработки запросов (rate limiting). Используя шлюзы API, можно улучшить масштабируемость и надежность системы. - Пересмотр микросервисной архитектуры
Если вышеуказанные решения не являются достаточными, может потребоваться пересмотр архитектуры микросервисов с целью снижения зависимостей и улучшения масштабируемости. Разбивая монолитные сервисы на более независимые микросервисы, можно улучшить масштабируемость и производительность системы.
Почему 10 вопросов про микросервисную архитектуру актуальная статья?
Как я уже упоминал, микросервисы стали неотъемлемой частью современной разработки программного обеспечения, особенно для разработки облачных приложений. От опытных разработчиков ожидается хорошее понимание общих проблем и вызовов, связанных с микросервисами. Вопросы на основе сценариев дают вам возможность познакомиться с этими проблемами, даже если вы не работали с микросервисной архитектурой в значительной степени.
Чтобы достичь успеха в разработке микросервисов, разработчикам следует хорошо разбираться в распределенных системах, архитектурных принципах и шаблонах проектирования. Они также должны быть знакомы с различными инструментами и технологиями, которые можно использовать для создания и управления микросервисами.
Одна важная рекомендация для опытных разработчиков, работающих с микросервисами, — быть в курсе последних тенденций и лучших практик в архитектуре микросервисов. Они также должны постоянно совершенствовать свои навыки через обучение, сертификации и участие в мероприятиях сообщества. Данная статья 10 вопросов про микросервисную архитектуру отражает актуальные вопросы на момент написания статьи. Через какое-то время тенденции поменяются и вы сможете найти другую подборку актуальных проблем.
Имея прочные знания в области микросервисов и постоянно учась и адаптируясь к новым вызовам, опытные разработчики могут успешно создавать надежные, масштабируемые и надёжные системы на основе микросервисов.
Эти сценарии и вопросы на решение проблем проверяют навыки разработчика в решении задач и понимание принципов архитектуры микросервисов, таких как устойчивость к сбоям, масштабируемость и устойчивость.
Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.